
Анализ данных по серии книг «Властелин колец»
Тема
Для анализа мной была выбрана серия книг «Властелин колец». В данном исследовании мной будут сравниваться частота употребления тех или и географических названий, имён и наименований рас.
Данные
С платформы Kaggle мной был взяты файлы с текстом Дж.Толкиена «Братство кольца», «Две крепости» и «Возвращение короля» и объединены в один txt файл.
Для написания кода мной был использован Google Colab.
Типы диаграмм
1. Столбчатая 2. Линейная 3. Точечная
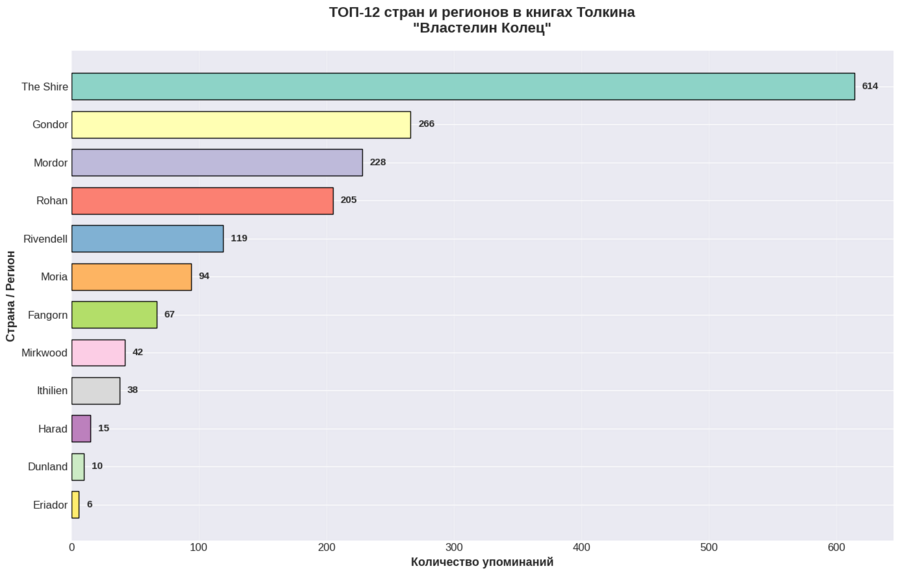
График 1
Мне хотелось проанализировать какие географические названия являются самыми популярными во всех трёх частях.
Для точности результатов мне для начала понадобилось разделить текст. С помощью регулярных выражений (re.compile) я искала заголовки «THE FELLOWSHIP OF THE RING», «THE TWO TOWERS» и «THE RETURN OF THE KING».
Также при работе с текстом мне понадобилось создать функцию count_occurrences (), которая использовала бы регулярные выражения для поиска точных совпадений слов с учетом их границ. Это позволило избежать подсчета частичных совпадений (например, «Gondor» в «Gondorian»). Для каждого анализируемого объекта (стран, рас, персонажей) были составлены списки ключевых слов и вариантов их написания.
Для корректного подсчета мне также понадобилось объеденить синонимы («Lothlórien» и «Lórien») через словарь Python. Результаты были сохранены в DataFrame Pandas.
График 2
Вторым моим шагом был анализ расового состава и визуализация того, как он менялся на протяжении всех трёх частей.
Мной был составлен словарь races с девятью расами и их вариантами написания на английском языке. Для каждой расы учитывал множественное число и синонимы (wizard» и «mage»).
График 3
Третьим моим шагом было проанализировать сколько раз употребляются наименования, связанные с родиной хоббитов по мере их продвижения к цели.
Для анализа динамики упоминаний мне понадобилось создать функцию count_occurrences_by_part (), которая подсчитывала частотность слов в каждой из трех частей отдельно. Это позволило проследить, как меняется упоминание Шира и Бэг Энда.
График 4
Четвёртым моим шагом был анализ того, как часто упоминается Саурон (антагонист) по мере приближения главных героев к нему.
Для этого мне также понадобилось создать функцию count_occurrences_by_part (). Это позволило отследить количество упоминаний Саурона и синонимичных ему слов по трём частям.
Вывод
1. В тройке лидеров по частоте упоминания находятся следующие регионы: Шир (родина главного героя), Гондор (финальное поле битвы) и Мордор (заключительная точка путешествия хоббитов), что объясняется их важностью для сюжета. 2. К началу Эпохи людей и финальной битве количество упоминаний их в тексте увеличивается. 3. Чем дальше хоббиты отходят от Шира и Бэг энда, тем реже они упоминаются в тексте, однако в заключительной части число этих наименований возрастает. 4. Чем ближе главные герои подходят к Саурону, тем больше его имя фигурирует в тексте.
Нейросети
В ходе работы мной были использованы следующие сервисы: 1. ChatGPT — для поиска ошибок в коде и их исправления.



