
Анализ данных о влиянии кофе на здоровье человека
О проекте
Кофе давно перестал быть просто напитком «чтобы проснуться». В современном городе он стоит наравне с чаем, но при этом вокруг кофе вырос целый культурный слой: количество кофеен растёт, а стаканчик с альтернативным молоком утром и днём стал почти визуальным символом определённого образа жизни — работы из ноутбука, фриланса, гибкого графика, «инстаграмной» повседневности. Кофе здесь работает одновременно как привычка, как ритуал и как социальный маркер.
На этом фоне я поймала себя на простой вещи: в последнее время я стала пить кофе чаще и заметно увеличила количество чашек в день. Вместе с этим появился вопрос, который звучит очень обыденно, но на мой взгляд явлется довольно исследовательским:
Кто пьёт кофе, в каких странах его употребляют «как воду», и самое важное — как регулярное потребление связано со сном и самочувствием человека?
Я хочу понять не «вредно/полезно» в общем виде, а увидеть паттерны: отличается ли эффект в зависимости от возраста, образа жизни, уровня стресса, физической активности.
Для анализа я взяла датасет Global Coffee Health Dataset с Kaggle: это большой набор на 10 000 подробных записей, который охватывает огромное количество аспектов.
Чтобы визуализации складывались в единый нарратив, я заранее определила набор графиков, каждый из которых отвечает на отдельный вопрос и даёт качественное понимание данных:
1. Линейная диаграмма используется, чтобы показать распределение потребления кофе по возрастным группам. Она позволяет увидеть общую картину: где сосредоточено большинство значений, есть ли пики и насколько заметны «хвосты» — то есть группы, в которых чаще встречается очень высокое потребление. 2. Сложенная линейная диаграмма применяется для визуализации связи между количеством кофеина и показателями сна. В таком формате удобно наблюдать, как меняется сон при росте кофеина и есть ли участки, где зависимость становится более выраженной или, наоборот, сглаживается. 3. Круговая диаграмма используется для сравнения стран по долям в выборке или по вкладу в общий объём потребления кофе (в зависимости от выбранной метрики). Она помогает быстро выделить страны с наибольшим «весом» в данных и обозначить фокус для дальнейшего анализа. 4. Столбчатая диаграмма предназначена для сравнения потребления кофе по профессиям. Этот график удобен для ранжирования категорий и наглядного сопоставления групп, чтобы увидеть, какие профессии связаны с более высоким потреблением и как это может сопоставляться со сном или стрессом. 5. Тепловая карта показывает поведенческий прокси, то есть некоторую зависимость количества чашек в день на количество кофеина в чашке.
Это позволит нам выделить типичные режимы потребления (условно: ради вкуса/потому что модно — много чашек при низком кофеине на чашку; ради бодрости — количество чашек при высокой дозировке), которые затем можно сопоставить с показателями сна и стресса.
Помимо этого я выбрала единую цветовую палитру из четырёх основных цветов. Это позволит нам воспринимать графики как единую систему, а также упрощать восприятие информации.
Пошаговый план работы
Я начала с импорта базовых библиотек (pandas, numpy, matplotlib) и загрузила датасет в Google Colab.
После чтения файла я вывела таблицу, чтобы быстро убедиться, что данные подгрузились корректно: строки не съехали, значения выглядят реалистично, а колонки отображаются как ожидается.
Дальше я привела названия колонок к удобному формату: убрала пробелы и дефисы, чтобы к полям можно было стабильно обращаться в коде. Затем с помощью кода я проверила наличие ключевых столбцов (возраст, страна, профессия, чашки, кофеин, сон и т. д.) и вывела результат в консоль. Это помогает не «угадывать», какие поля есть в таблице, и сразу увидеть, готов ли датасет к дальнейшим шагам.
После этого я сделала минимальную очистку:
1. числовые поля перевела в numeric, чтобы избежать ситуаций, когда числа считываются как строки; 2. категориальные поля перевела в category, чтобы группировки работали быстрее и стабильнее; 3. удалила дубликаты строк; 4. убрала строки без ключевых значений (возраст, чашки, кофеин, сон, страна, профессия), потому что без них выбранные графики просто не построятся корректно.
На выходе я получила df2 — базовый «чистый» датафрейм, на котором строится весь проект.
На последнем этапи подготовки я создала несколько вспомогательных признаков, которые упрощают анализ:
1. Age_group — возрастные группы для сравнений; 2.Coffee_bin — уровни потребления по чашкам (если понадобится для дополнительных разрезов); 3.Caffeine_per_cup — «кофеин на чашку» как поведенческий прокси (чтобы отличать режимы потребления).
Отдельно я настроила визуальный стиль в соответсвии с тем, что я указала ранее.
Визуализация данных
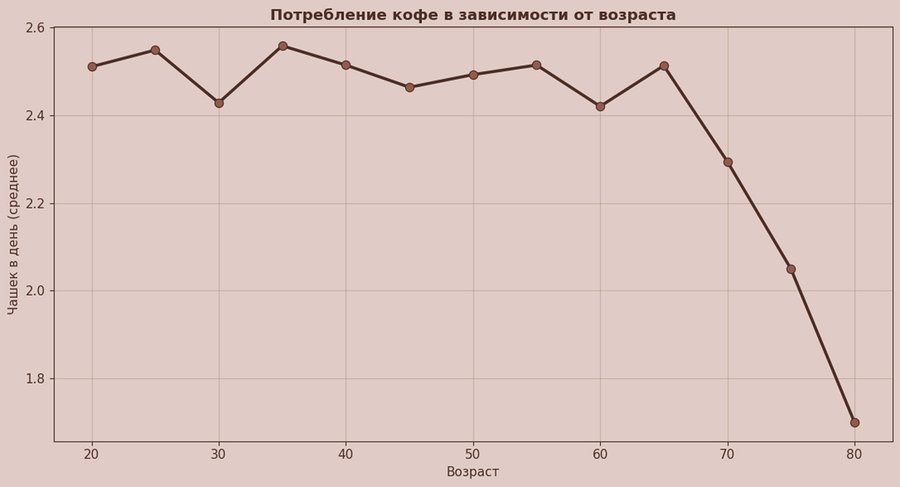
Этот график отвечает на самый базовый вопрос: как меняется среднее потребление кофе с возрастом. Я сгруппировала возраст по шагу 5 лет и посчитала среднее число чашек в день для каждого интервала. Вместо столбцов я использовала линию с маркерами, чтобы график читался как плавная зависимость, а точки подчёркивали, что кривая построена по реальным агрегированным значениям.
Из графика можно понять, что до, примерно, 65 лет потребление остаётся почти ровным — в районе 2.4–2.55 чашки в день, без выраженного роста или падения. Самое заметное изменение начинается после 70: линия резко уходит вниз (примерно 2.3 к 70, около 2.05 к 75 и ~1.7 к 80). То есть в этом датасете возраст влияет не «постепенно», а скорее проявляется как спад в старших группах.

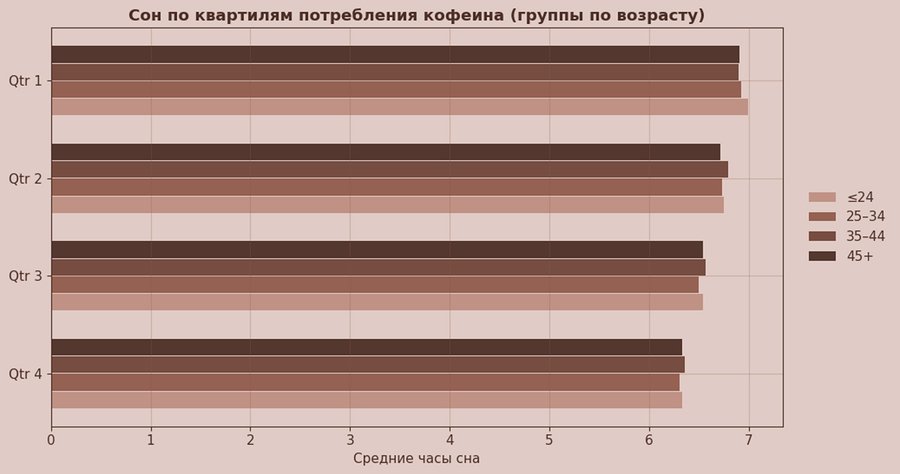
Здесь я перехожу от «кто сколько пьёт» к вопросу как кофеин соотносится со сном. Я разделила значение Caffeine_mg на 4 квантили (Qtr 1–Qtr 4) и посчитала средние часы сна внутри каждой квантильной группы. Дополнительно я выделила возрастные категории (≤24, 25–34, 35–44, 45+), чтобы увидеть, одинаково ли работает связь «кофеин — сон» в разных возрастах.
Формат горизонтальных групповых баров выбран потому, что он хорошо показывает сравнение нескольких серий в каждой категории и выглядит информативно: можно быстро считывать разницу между группами.
Так во всех возрастных группах видно единое направление: от Qtr 1 к Qtr 4 средняя длительность сна уменьшается. Разница небольшая, но стабильная: примерно с ~6.9–7.0 часов в первом квартиле до ~6.3–6.4 часов в четвёртом. Возрастные группы при этом отличаются слабее, чем квартиль кофеина: внутри каждого квартиля значения близки между собой, а главный сдвиг задаёт именно уровень кофеина.
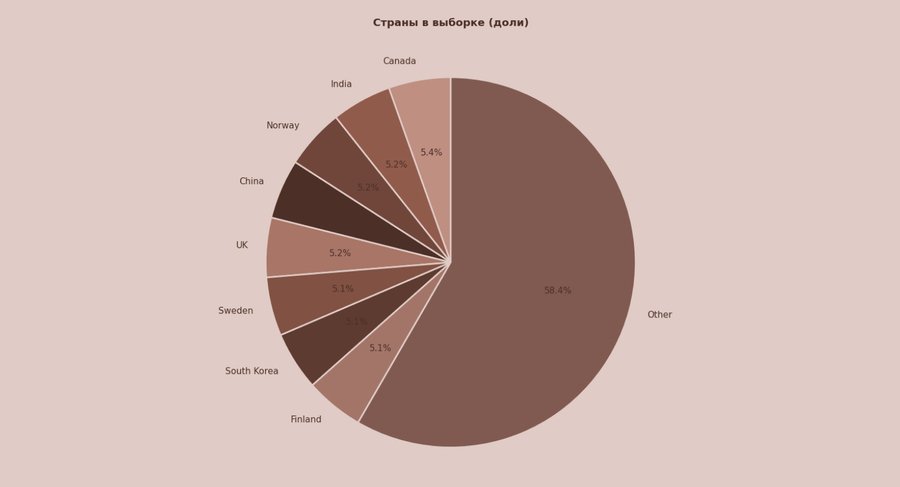
Круговую диаграмму я использовала как обзорный снимок: из каких стран состоит выборка. Я взяла топ-8 стран по числу наблюдений и объединила остальные в категорию Other, чтобы график не превращался в перегруженную легенду. Такой формат помогает сразу увидеть, какие страны задают основной вес данных и на что стоит обращать внимание при интерпретации результатов.
Вывод по графику: распределение похоже на длинный хвост: категория Other занимает ~58.4%, а отдельные страны из топа дают примерно по ~5% каждая (разброс очень небольшой — около 5.1–5.4%). Это значит, что выборка не «держится» на одной стране (кроме агрегированного Other), а разложена довольно равномерно между множеством стран. Для интерпретации это важно: разрез по странам здесь скорее показывает структуру датасета, чем ярко выраженную географическую доминанту.

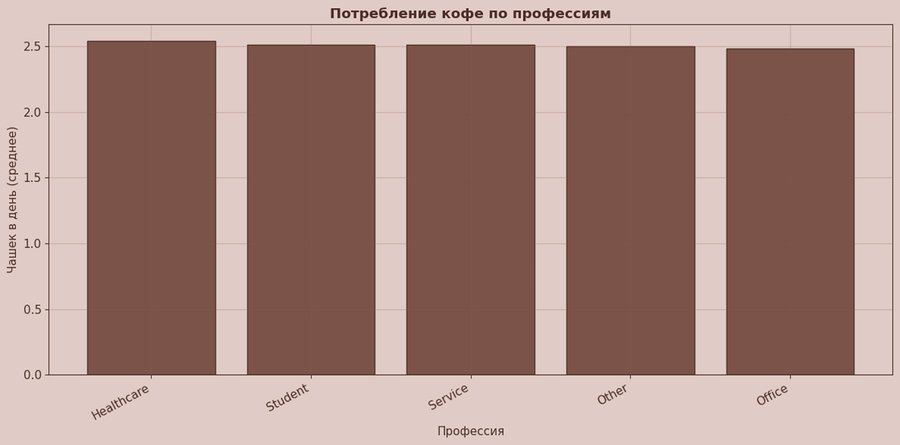
Этот график отвечает на вопрос кто пьёт больше по профессиональному контексту. Я сгруппировала данные по профессиям и посчитала среднее число чашек в день, оставив топ-15 профессий по числу наблюдений (чтобы сравнение было корректным и читаемым). Затем я отсортировала профессии по среднему значению — так график читается как рейтинг.
Различия между профессиями получились минимальными: почти все значения держатся около ~2.5 чашки в день, а разрыв между крайними столбцами визуально небольшой (порядка нескольких десятых). В рамках этого датасета профессия выглядит не как сильный фактор потребления — по крайней мере, если смотреть именно на среднее число чашек.
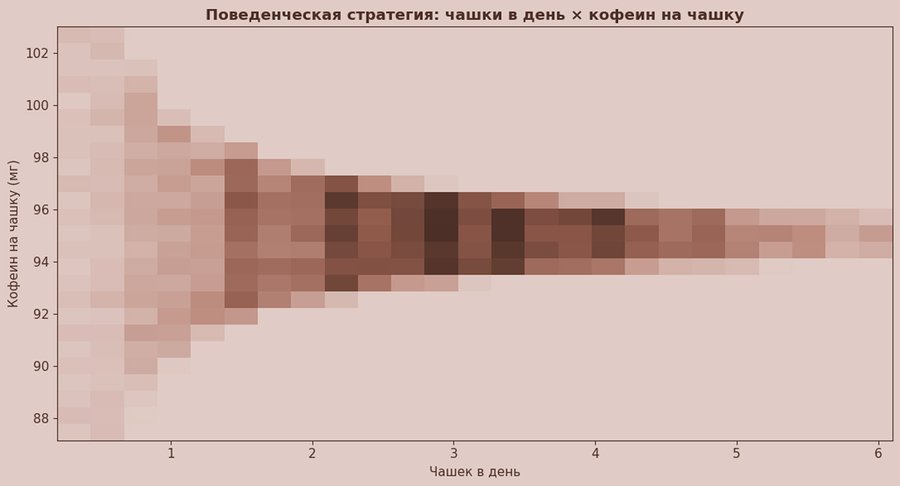
Прямого поля «зачем пьют кофе» в датасете нет, поэтому я сделала поведенческий прокси: X = чашки в день, Y = кофеин на чашку (Caffeine_per_cup). Тепловая карта показывает, где в данных находится основная концентрация наблюдений, то есть какие режимы потребления встречаются чаще. Перед построением я ограничила экстремальные значения по квантилям (1% и 99%), чтобы редкие выбросы не сломали масштаб и не сделали картинку нечитаемой.
Тут можно заметить «сходимость» по мере роста числа чашек. При низком потреблении (примерно до 1 чашки/день) кофеин на чашку распределён широко — встречаются и более слабые, и более крепкие режимы. А при более высоком потреблении (~3–6 чашек/день) значения сжимаются в узкий коридор около ~94–96 мг на чашку. Это похоже на компенсаторную стратегию: когда чашек становится больше, крепость одной чашки чаще «нормализуется» и перестаёт сильно прыгать.
Заключение
В этом проекте я последовательно посмотрела на кофе как на повседневную практику: кто и как часто его пьёт, и что происходит с базовыми показателями вроде сна.
Сначала я проверила, как потребление связано с возрастом. На графике видно, что до примерно 60–65 лет среднее количество чашек в день почти не меняется и держится на одном уровне. Самая заметная точка сдвига появляется позже: после 70 лет потребление начинает резко снижаться, и именно этот возрастной диапазон задаёт общий перелом линии.
Затем я перешла к вопросу, который был для меня центральным: как кофеин соотносится со сном. Когда выборку делят на квантили по уровню кофеина, во всех возрастных группах проявляется одна и та же динамика: от первого квартиля к четвёртому средняя длительность сна уменьшается. Разница не выглядит экстремальной, но она повторяется стабильно, поэтому воспринимается как устойчивый паттерн внутри данных.
Дальше я проверила профессиональный контекст. Здесь ожидалось, что различия могут быть сильнее, но график показывает почти ровное распределение: средние значения по профессиям очень близки. Это стало отдельным результатом — в рамках этого датасета профессия не объясняет потребление так хорошо, как можно было предположить.
Чтобы понимать, как устроена сама выборка, я добавила страновой разрез. Он показывает, что данные распределены по множеству стран и большая часть наблюдений собрана в категории Other, а топ-страны имеют близкие доли. Это задаёт рамку для интерпретации: страновой фактор здесь важен скорее как контекст, чем как источник резких различий.
Наконец, я попыталась приблизиться к вопросу «зачем пьют кофе» через поведение: совместила количество чашек и кофеин на чашку. Тепловая карта показывает, что при большем числе чашек крепость одной чашки чаще стабилизируется в узком диапазоне. В итоге получается цельная картина: потребление кофе в большинстве возрастов довольно стабильно, но в старших группах снижается; уровень кофеина связан с сокращением сна; а режим потребления чаще выглядит как настроенная стратегия, а не просто случайное увеличение дозы.
Использованные инструменты
Kaggle — источник данных для анализа (табличный CSV-файл). (https://www.kaggle.com/datasets/uom190346a/global-coffee-health-dataset?resource=download)
Google Colab — среда, где я запускала код, работала с ноутбуком и сохраняла графики.
Pandas — загрузка CSV (read_csv), очистка данных (пропуски/дубликаты), приведение типов, группировки (groupby), расчёт средних значений и подготовка таблиц для графиков.
NumPy — числовые операции (квантильные ограничения, бины, расчёт 2D-гистограммы для тепловой карты).
Matplotlib — построение и стилизация всех графиков (палитра, фон, шрифты/подписи, сетка).
Chat GPT 5.2 — для корректировки кодов



