
Глобальная динамика ментального здоровья: Анализ уровня суицидов
Концепция
Самоубийство остаётся одной из самых острых проблем общественного здоровья: оно связано с экономическими кризисами, культурным контекстом и доступностью психологической помощи. При этом в публичном поле тема ментального здоровья часто подаётся фрагментарно и эмоционально, без опоры на долгосрочные данные.
В своём исследовании я анализирую глобальные статистические данные о смертности от суицидов в разных странах мира с 2000 по 2021 год. Датасет содержит информацию о количестве суицидов на 100 000 человек населения по годам для более чем 190 государств. Такой временной горизонт позволяет увидеть не только моментальные всплески, но и долгие траектории изменения этих показателей.
Выбор данных и источник
Для анализа я использовала датасет World Suicide Mortality Data 2000–2021, доступный на Kaggle и основанный на статистике Всемирного банка и Всемирной организации здравоохранения. В работе задействованы три ключевых поля: название страны, год и уровень суицидальной смертности на 100 000 человек. Выбор именно этого датасета обусловлен глобальным охватом — позволяет выявить как универсальные паттерны, так и региональные различия, и достаточной временной глубиной — 21 год истории позволяет отследить воздействие значительных исторических событий (финансовый кризис 2008 г., пандемия COVID-19 2019–2021 гг.) Датасет изначально включал не только отдельные страны, но и агрегированные регионы («Europe & Central Asia», «High income» и т. п.). Чтобы не искажать визуализацию, эти агрегаты были удалены: в итоговом анализе участвуют только суверенные государства.
Выбранные типы визуализаций и их обоснование
Линейный график
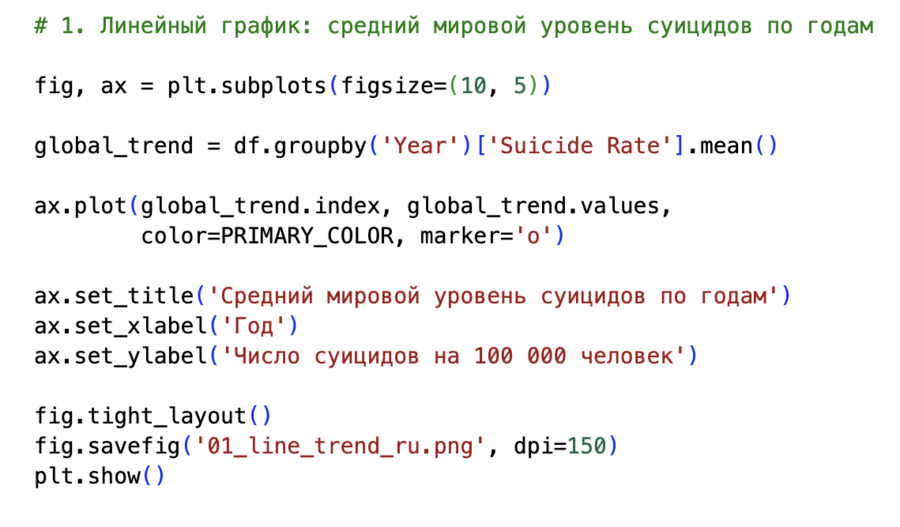
— показывает средний мировой уровень суицидов по годам и отдельную траекторию России. Это самый наглядный способ увидеть общий тренд и его изменение во времени.Горизонтальные столбчатые диаграммы
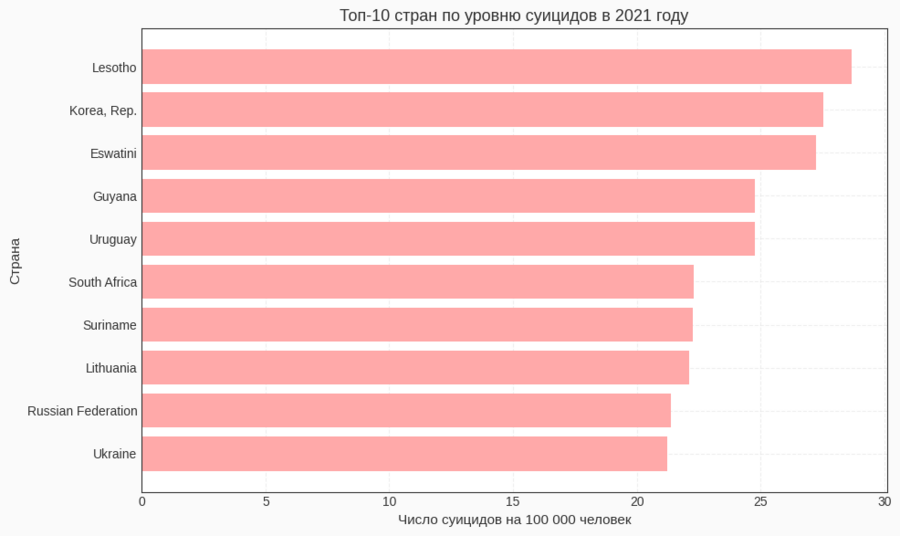
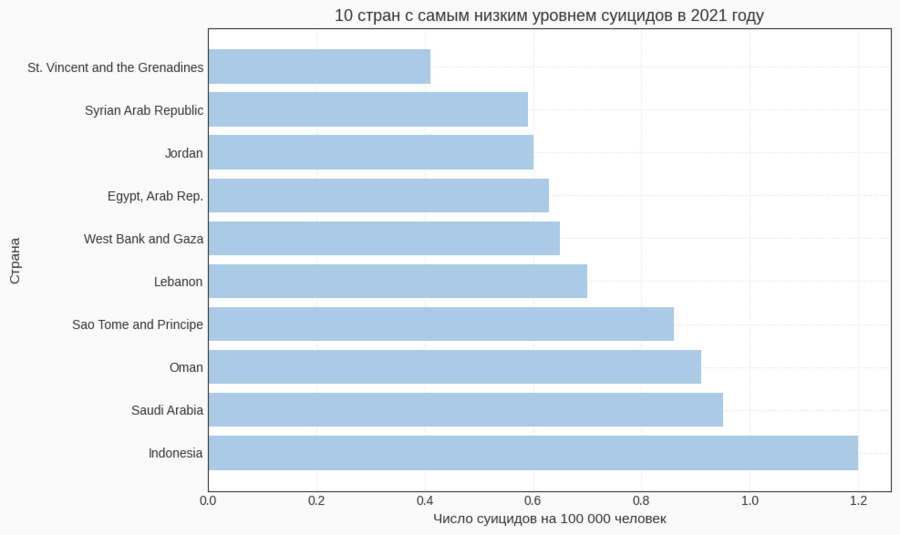
— две диаграммы для стран с наиболее высокими и наиболее низкими уровнями в 2021 году. Такой формат удобен для считывания ранжирования и сравнений между странами.Гистограмма
— демонстрирует распределение стран по уровню суицидов в 2021 году. Она позволяет увидеть, где располагается «большинство», а где находятся исключения с очень высокими значениями.Столбчатая диаграмма изменений
— сравнивает уровень суицидов в 2000 и 2021 годах и показывает топ стран, где ситуация сильнее всего улучшилась или ухудшилась. В отличие от диаграммы рассеяния, такой формат проще для восприятия: зритель считывает только направление и величину изменений.
Визуальный стиль выстроен вокруг двух элементов: палитры и типографики. В качестве основной палитры использованы: 1)светло-синий #AACAE6 для линий и ключевых акцентов; 2)мягкий розовый #FFA9A9 для выделения стран с ростом показателей; 3)нейтральный серый #888888 для второстепенных элементов;
Такое сочетание позволяет одновременно поддерживать серьёзность темы и избегать агрессивных или слишком драматичных цветовых решений. Синий и серый ассоциируются с аналитикой и спокойствием, а мягкий розовый используется как предупредительный акцент для стран, где ситуация ухудшается. Для шрифта выбран IBM Plex Mono — современный моноширинный шрифт, разработанный IBM. Он хорошо работает с кириллицей и даёт ощущение «технического отчёта» или консольного вывода, что усиливает впечатление системности и аналитичности. Шрифт подключается в среде Google Colab через загрузку файла IBMPlexMono-Regular.ttf и добавление его в менеджер шрифтов matplotlib, после чего он задаётся как основной для всех подписей и заголовков.
Для обложки проекта я использовала генеративную модель изображений Midjourney v.7, сформулировав промт в лаконичной, метафорической форме: abstract minimalist illustration, human silhouette dissolving into small particles or fragments that drift upward, background in dark muted blue, gentle light around the figure, expressive but understated, no text
В этом описании нет прямых отсылок к насилию или самоповреждению: человеческая фигура изображается абстрактно, она как бы растворяется в темном пространстве, превращаясь в частицы. Подъём этих частиц вверх создаёт ощущение одновременно исчезновения и лёгкого, почти незаметного освобождения. Тёмный, приглушённый синий фон обложки рифмуется с основным синим цветом в визуализациях, а мягкий свет вокруг фигуры намекает на хрупкую, но всё же присутствующую возможность поддержки и выхода. Минимализм и отсутствие текста позволяют вынести в центр именно эмоциональный подтекст темы, а не буквальное изображение статистики.
Обработка и визуализация данных
Сначала я импортировала pandas, matplotlib.pyplot, matplotlib.rcParams и загрузила CSV‑файл. Затем составила список всех агрегированных регионов и доходных групп, которые присутствуют в столбце Country Name. Этот список был передан в метод isin (), после чего строки с такими значениями были исключены из датасета. Это обеспечило корректность всех последующих группировок и сравнения именно между странами, а не между странами и «средними по миру» величинами.


Для построения линейного графика среднемирового уровня я использовала группировку по году: groupby ('Year')['Suicide Rate'].mean (). Полученный временной ряд служит основой для первого графика, где виден общий спад уровня суицидов за 21 год.
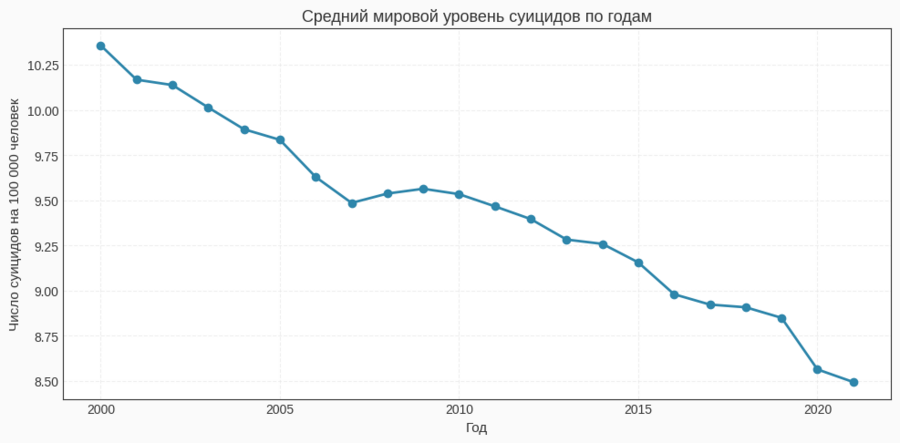
Для диаграмм «топ‑10» и «анти‑топ‑10» я отфильтровала данные за 2021 год (df[df['Year'] == 2021]), отсортировала по столбцу Suicide Rate и с помощью head (10) выбрала первые десять строк. Эти данные используются в двух горизонтальных bar‑графиках: один показывает страны с самыми высокими показателями, другой — с самыми низкими.


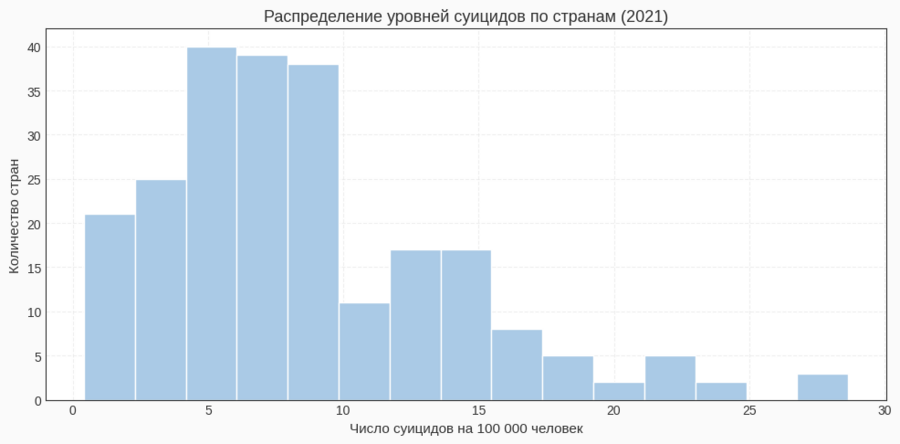
Для гистограммы я взяла столбец Suicide Rate за 2021 год и передала его в plt.hist с 15 бинами. Такой шаг позволяет оценить, как распределяются страны по уровню суицидов: сгруппированы ли они около низких значений или распределены равномерно.
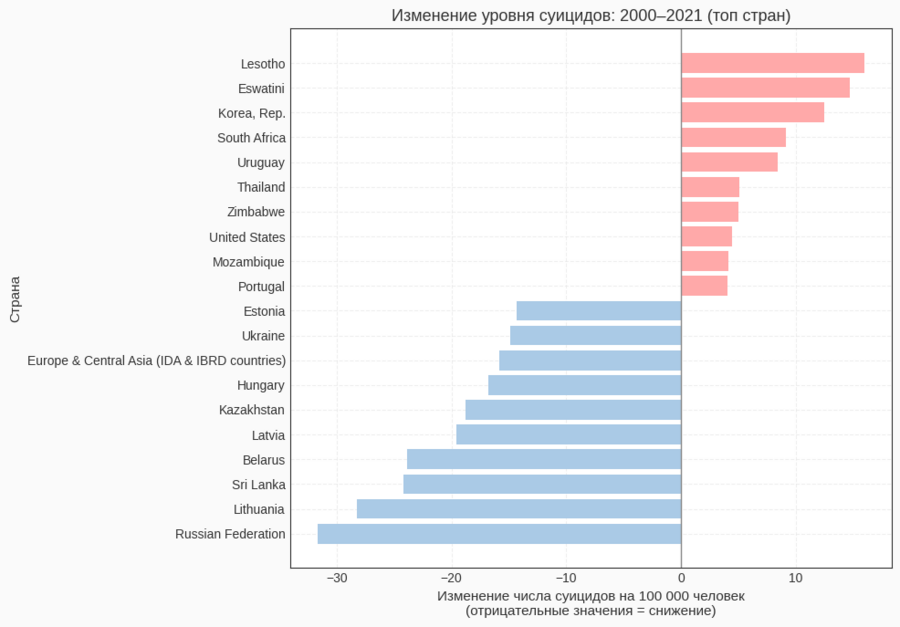
Чтобы сравнить уровни в двух временных точках, я построила сводную таблицу: pivot_table (index='Country Name', columns='Year', values='Suicide Rate'). После этого были выбраны только столбцы 2000 и 2021 годов, а строки с пропусками удалены. Новая колонка change рассчитывается как разность 2021 — 2000. По ней формируется два списка стран: с наибольшим снижением (отрицательные значения) и с наибольшим ростом (положительные). На их основе строится горизонтальная столбчатая диаграмма, в которой цвет столбцов показывает направление изменения.
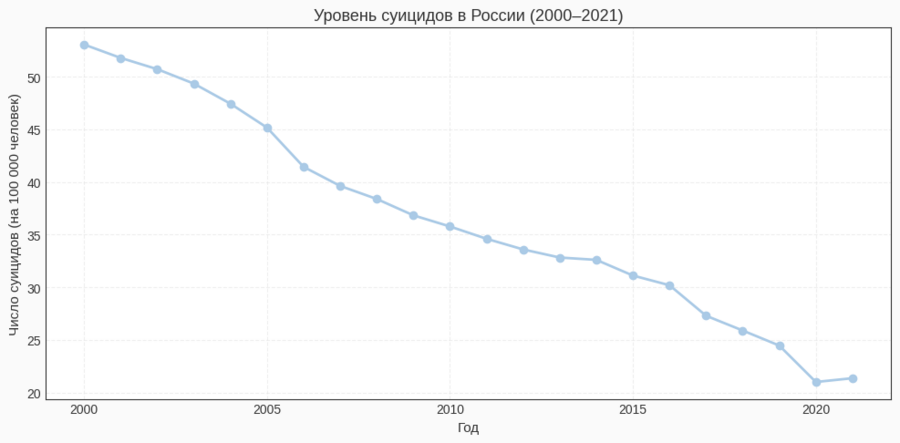
Для России был создан отдельный срез по строкам с Country Name == 'Russian Federation', отсортированный по году. На основе этого временного ряда построен линейный график, позволяющий увидеть динамику уровня суицидов именно в российском контексте.
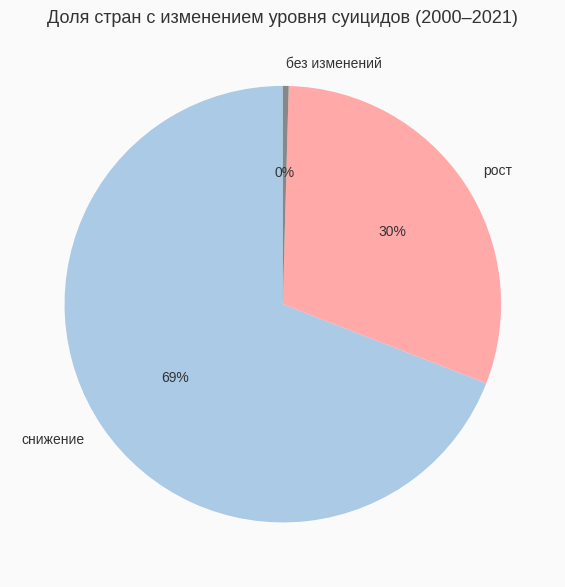
Круговая диаграмма построена на основе уже рассчитанной величины change (разница между уровнем суицидов в 2000 и 2021 годах для каждой страны). Я разделила все страны на три группы: те, где показатель снизился, вырос или практически не изменился. В коде это выражено через подсчёт количества значений change меньше нуля, больше нуля и равных нулю. Полученные числа были переданы в ax.pie вместе с подписи «снижение», «рост» и «без изменений». Эта диаграмма не добавляет новых «сырых» данных, но пересобирает уже имеющуюся информацию в максимально компактную, интуитивную форму: одним взглядом видно, какая доля стран движется в сторону улучшения, а какая — в сторону ухудшения. В моём случае большинство сегмента диаграммы занимает зона «снижение», что визуально подчёркивает позитивный тренд, о котором говорят и другие графики.
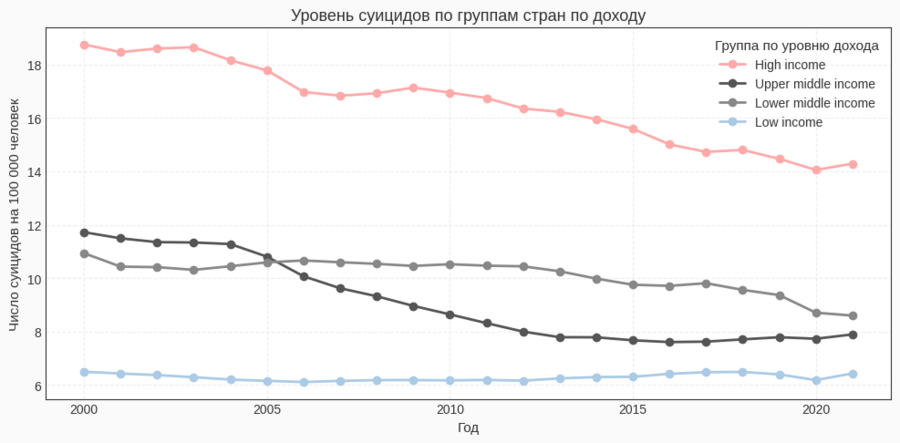
Отдельный набор визуализаций я посвятила сравнению стран не по географическому признаку, а по уровню дохода — в соответствии с классификацией Всемирного банка. Для этого я временно не удаляла агрегированные строки High income, Upper middle income, Lower middle income, Low income и собрала из них отдельный датафрейм income_df. Затем для каждой из четырёх групп был построен собственный временной ряд (год → уровень суицидов), и все четыре линии отображены на одном графике. Код использует простой цикл по списку groups: для каждой группы фильтруются строки, и вызывается ax.plot с отдельным цветом и подписью. Легенда оформлена как «Группа по уровню дохода». Этот график показывает, что высокий уровень официально зарегистрированных суицидов характерен прежде всего для группы стран с высоким доходом, тогда как в странах с низким доходом показатели ниже.
График показывает, что официально зарегистрированный уровень суицидов выше в группе стран с высоким доходом, чем в группах с низким и средним доходом. Это не означает, что индивидуальные «богатые люди» чаще совершают суицид: агрегированные данные по странам смешивают в себе качество учёта, культурные различия и структуру населения. Тем не менее, визуализация подчёркивает, что высокий уровень экономического развития сам по себе не гарантирует низких показателей суицидальной смертности.
Выводы
В процессе работы с мировым датасетом по суицидальной смертности я построила несколько типов диаграмм, которые показывают динамику проблемы во времени, различия между странами и масштабы изменений за последние два десятилетия. Вместо одного «идеального» портрета я получила многослойную картину, где важны и глобальные тренды, и локальные истории отдельных стран.
Если собрать вместе ключевые наблюдения из графиков, получается следующий образ мира:
- В среднем по миру уровень суицидов медленно, но заметно снижается;
- При этом сохраняется группа стран с очень высокими показателями, которые сильно выбиваются из общего распределения;
- Россия входит в число стран, где показатели за 2000–2021 годы значительно снизились, но по-прежнему остаются высокими по сравнению со многими другими государствами;
- Экономическое благополучие страны само по себе не гарантирует низкий уровень суицидов: группа «high income» стабильно держится на верхних позициях по официальной статистике.
Проект не даёт простого ответа, «как сделать, чтобы суицидов не было», но помогает увидеть, что за сухими цифрами стоит много разных траекторий и что даже глобальный положительный тренд не отменяет необходимости адресной работы с уязвимыми группами и контекстами.
Описание применения генеративной модели
В работе над этим проектом я использовала несколько генеративных моделей как вспомогательные инструменты на разных этапах. Языковые модели (в том числе ChatGPT 4o и Gemini 3) помогали структурировать этапы обработки данных: формулировать фильтры для удаления агрегированных регионов, настраивать группировки и сводные таблицы, а также сокращать и упрощать код построения диаграмм.
Те же модели я привлекала для проработки визуального стиля: с их помощью были предложены варианты цветовой палитры, идея использования шрифта IBM Plex Mono и единые параметры оформления графиков, чтобы все изображения выглядели как части одного аналитического отчёта. Кроме того, языковые модели помогали формулировать текстовые блоки — от общей концепции исследования до комментариев к отдельным графикам, а также подбирать метафорические формулировки промта для обложки.
Для генерации самой обложки проекта использовалась модель Midjourney v7: на основе текстового промта была создана абстрактная иллюстрация с растворяющимся человеческим силуэтом и тёмно‑синим фоном. При этом окончательный выбор решений, интерпретация данных и редактирование текстов оставались за мной: генеративные модели предлагали варианты, а я отбирала и адаптировала их под свои исследовательские задачи и этический тон проекта.



