
От «Истории игрушек» до «Элементарно»: Динамика успеха Pixar
Концепция
Анимационные фильмы Pixar завоевали сердца зрителей по всему миру благодаря своим уникальным сюжетам, визуальной красоте и высоким кассовым сборам. В этом проекте мы решили проанализировать данные о фильмах студии, чтобы увидеть, какие факторы влияют на их успех, как менялась популярность студии с годами и как оценивали фильмы зрители и критики. Исследование включает визуализацию ключевых показателей, таких как кассовые сборы, рейтинги и бюджеты, чтобы лучше понять динамику развития Pixar.

Я использовала данные о фильмах Pixar, включая информацию о годах выпуска, бюджетах, кассовых сборах и оценках с различных платформ. Анализ основан на датасете Pixar Films Dataset, найденный на платформе Kaggle, который содержит сведения о коммерческом успехе и критическом восприятии фильмов.
Для анализа я выбрала распределение фильмов по годам, чтобы выявить активность студии, сравнение бюджетов и сборов для оценки эффективности вложений, анализ оценок на разных платформах и тренды кассовых сборов по годам.

Для визуализации были выбраны яркие цвета в духе Pixar. В частности, основные цвета палитры были вдохновлены мультиком «Головоломка», для большего погружения в атмосферу.
Для визуализации данных Pixar были использованы гистограммы (распределение количества фильмов по годам), диаграммы рассеяния (анализ связи бюджета и кассовых сборов), ящичные диаграммы (сравнение оценок на разных платформах) и линейные графики (тренды кассовых сборов).
Обработка данных
В коде использованы библиотеки: pandas для обработки данных в формате CSV, matplotlib.pyplot для построения графиков, seaborn для стилизации визуализаций.
Перед началом работы с данными я подготовила датасет для последующего анализа.
Сначала я импортировала библиотеки pandas, matplotlib.pyplot и seaborn, которые необходимы для обработки данных и их визуализации.
Далее, я загрузила датасет с помощью pd.read_csv ('pixar_films new.csv'), преобразовав его в формат DataFrame. Затем я проверила корректность загрузки с помощью print (df.head ()), что позволило мне убедиться, что данные читаются правильно.
Для предварительной обработки данных я очистила названия столбцов от лишних пробелов (df.columns = df.columns.str.strip ()) и удалила строки с пропущенными значениями (df = df.dropna ()).
Так как в датасете дата выхода фильма была записана в текстовом формате, я преобразовала её в тип даты (pd.to_datetime (df['release_date'], errors='coerce')). После этого я выделила год выпуска фильма (df['release_year'] = df['release_date'].dt.year), что позволяет строить графики по годам и анализировать динамику.
Визуализация данных
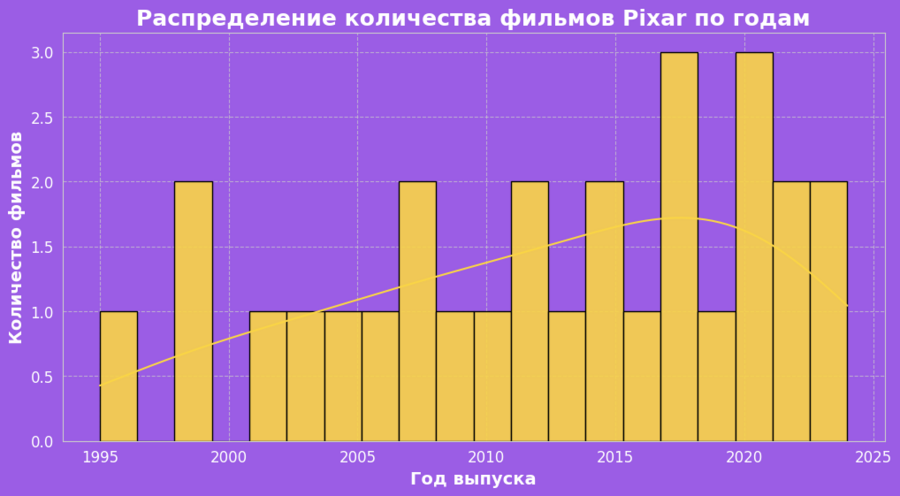
Гистограмма: распределение фильмов по годам
Гистограмма показывает, как изменялось количество выпущенных фильмов Pixar с течением времени. Видно, что в первые годы студия выпускала фильмы редко, но начиная с 2000-х годов производство стало более стабильным, с пиком в 2010-х.

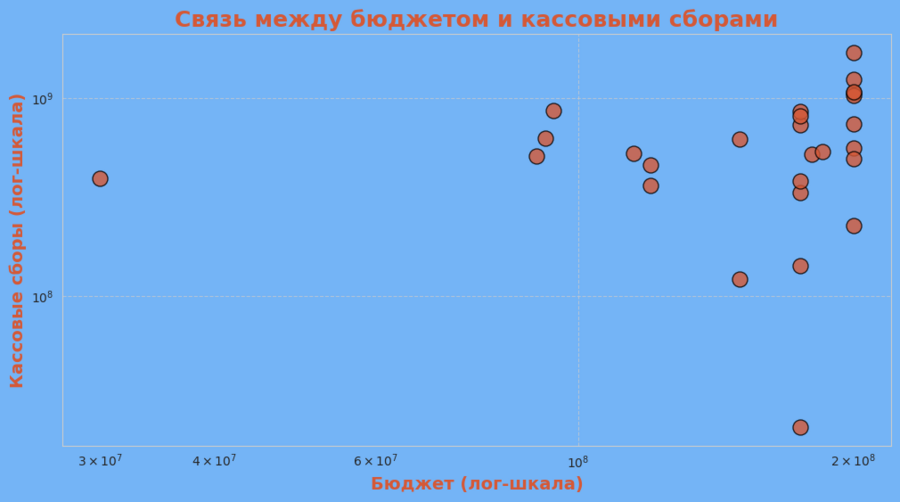
Диаграмма рассеяния: бюджет vs кассовые сборы
Диаграмма рассеяния отображает зависимость между бюджетом фильма и его мировыми кассовыми сборами. Видно, что большинство фильмов с высоким бюджетом имеют высокие сборы, но не всегда бюджет является определяющим фактором успеха — некоторые фильмы с меньшими затратами показывают хорошие результаты.
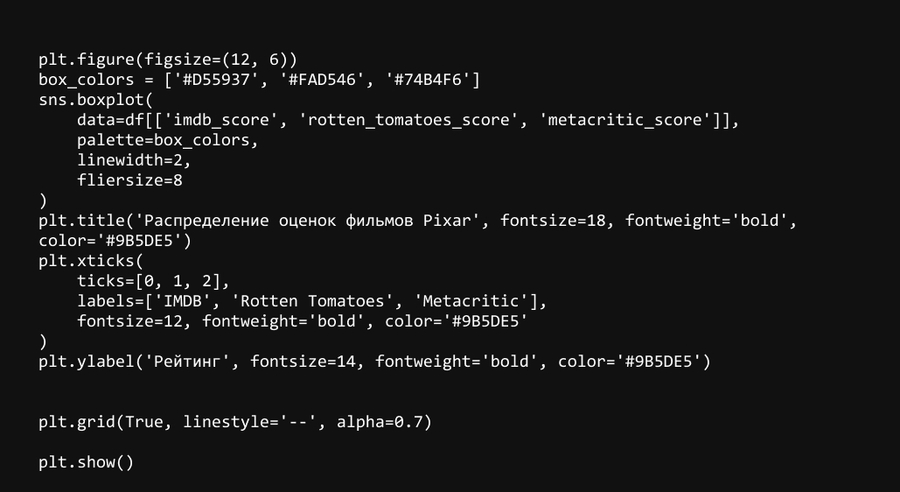
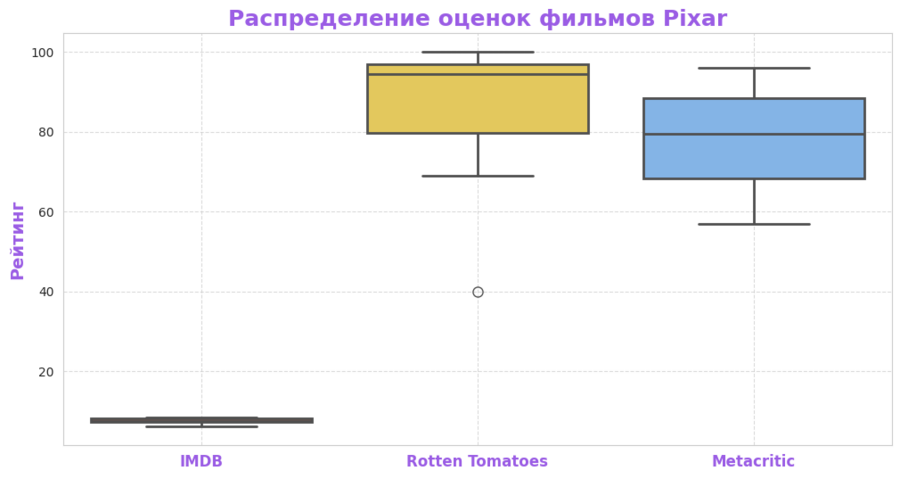
Ящичная диаграмма: оценки на разных платформах
Ящичная диаграмма показывает различия в оценках фильмов Pixar на трех платформах: IMDB, Rotten Tomatoes и Metacritic. Rotten Tomatoes обычно выставляет более высокие оценки, тогда как Metacritic имеет больший разброс, что говорит о более критическом подходе к рецензиям.

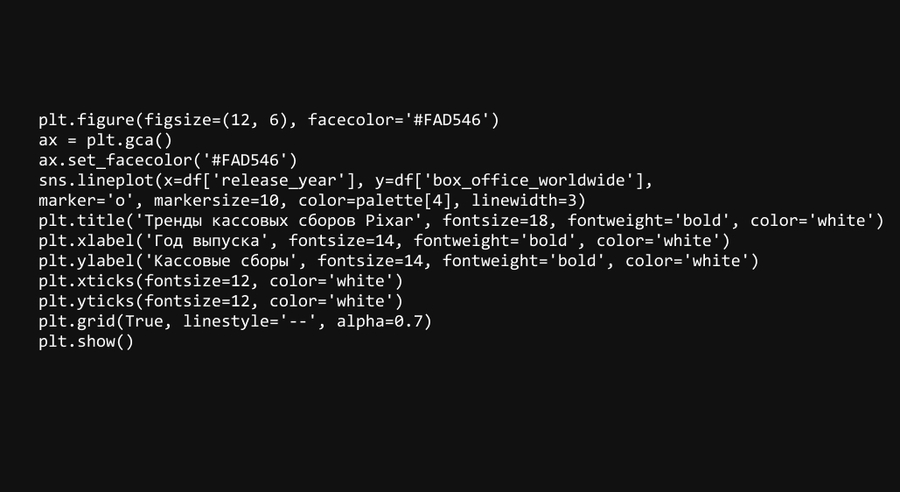
Линейный график: кассовые сборы по годам
Линейный график показывает, как изменялись кассовые сборы Pixar с годами. Видно, что некоторые фильмы значительно превышали сборы предыдущих, особенно в периоды выхода культовых фильмов, таких как «История игрушек», «В поисках Немо» и «Холодное сердце». Общий тренд показывает рост доходов студии со временем.
Список источников
Датасет и блокнот с кодом



