
Введение
Я прочитала много произведений В. В. Набокова, поэтому в этом проекте мне показалось интересным сравнить его интервью с разницей в 10 лет. Я нашла интервью 1962 и 1972 года на сайте lib.ru. Для визуализации данных использовались гистограммы и линейные графики, в данном случае это были самые наглядные графики для сравнения материала.
Этапы работы
Сначала я импортировала файлы с текстом из библиотеки, потом считывала их, анализировала и строила графики.
Сравнение самых часто встречающихся слов
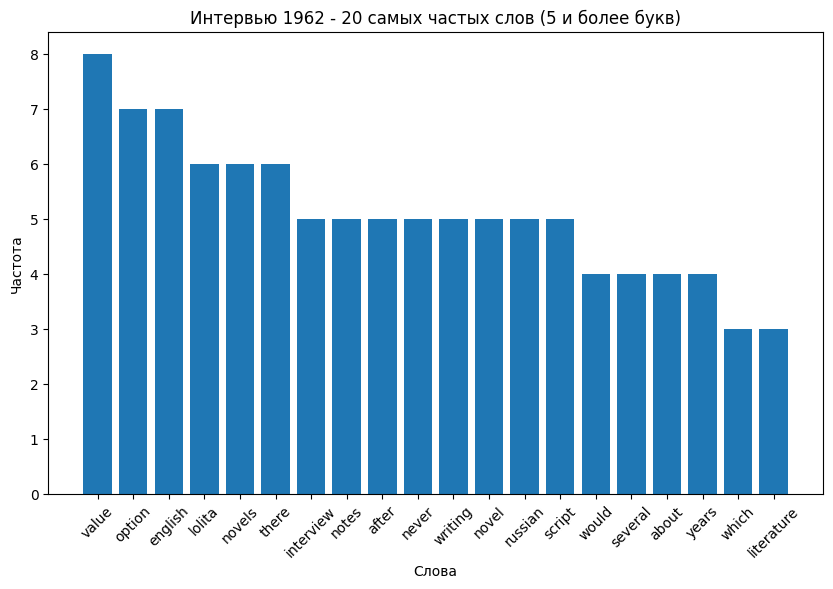
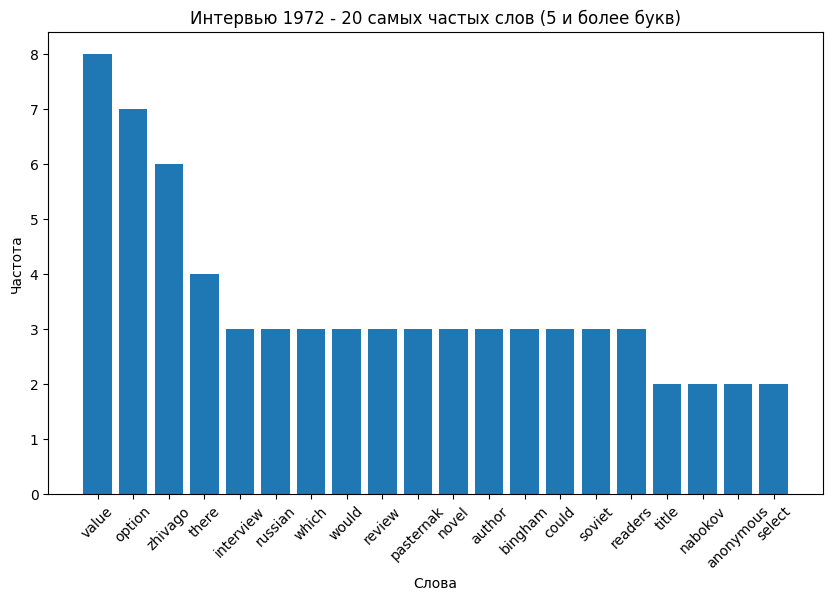
Также использовалась нейросеть ChatGPT для исправления ошибок, которые возникали по ходу работы с кодом, и комментирования процесса работы.
import re import matplotlib.pyplot as plt
Функция для загрузки текста из файла
def load_text (file_path): with open (file_path, encoding='utf-8', errors='ignore') as f: return f.read ()
Функция для разбивки текста на строки, а затем на слова
def split_text_into_lines_and_words (text): # Разбиваем текст на строки lines = text.splitlines () # Это разделяет текст по символам новой строки
# Разбиваем каждую строку на слова
lines_and_words = []
for line in lines:
words = re.findall (r'\b\w+\b', line.lower ()) # Находим слова, игнорируя пунктуацию
lines_and_words.append (words)
return lines_and_words
Функция для подсчета частоты слов длиной 5 и более букв
def word_frequency (lines_and_words, min_length=5): freq = {} for line in lines_and_words: for word in line: if len (word) >= min_length: # Фильтруем слова по длине if word in freq: freq[word] += 1 else: freq[word] = 1 return freq
Функция для построения графика
def plot_word_frequencies (word_freq, title): # Сортируем словарь по частоте в порядке убывания sorted_f
Сравнение количества позитивных слов
import re import matplotlib.pyplot as plt
Список позитивных слов на английском
positive_words = {'good', 'wonderful', 'great', 'excellent', 'happy', 'positive', 'joy', 'friendly', 'love', 'success'}
Функция для загрузки текста из файла
def load_text (file_path): with open (file_path, encoding='utf-8', errors='ignore') as f: return f.read ()
Функция для разбивки текста на строки и слова
def split_text_into_lines_and_words (text): # Разбиваем текст на строки lines = text.splitlines () # Это разделяет текст по символам новой строки
# Разбиваем каждую строку на слова
lines_and_words = []
for line in lines:
words = re.findall (r'\b\w+\b', line.lower ()) # Находим слова, игнорируя пунктуацию
lines_and_words.append (words)
Функция для подсчета количества позитивных слов
def count_positive_words (lines_and_words, positive_words): positive_count = 0 for line in lines_and_words: for word in line: if word in positive_words: positive_count += 1 return positive_count
Функция для построения графика сравнения количества позитивных слов
def plot_positive_word_comparison (count1, count2, title1, title2): # Строим график для сравнения plt.figure (figsize=(8, 5)) plt.bar ([title1, title2], [count1, count2], color=['green', 'blue']) plt.xlabel ('Интервью') plt.ylabel ('Количество позитивных слов') plt.title (f’Сравнение количества позитивных слов\n{title1} vs {title2}') plt.show ()
Загрузка текста из файлов
interview1_text = load_text ('Inter01.txt') interview2_text = load_text ('Inter22.txt')
Разбиваем тексты на строки и слова
interview1_lines_and_words = split_text_into_lines_and_words (interview1_text) interview2_lines_and_words = split_text_into_lines_and_words (interview2_text)
Подсчитываем количество позитивных слов для обоих интервью
interview1_positive_count = count_positive_words (interview1_lines_and_words, positive_words) interview2_positive_count = count_positive_words (interview2_lines_and_words, positive_words)
Выводим количество позитивных слов для обоих интервью
print (f"В интервью 1 {interview1_positive_count} позитивных слов.») print (f"В интервью 2 {interview2_positive_count} позитивных слов.»)
Строим график сравнения количества позитивных слов
plot_positive_word_comparison (interview1_positive_count, interview2_positive_count, 'Интервью 1962', 'Интервью 1972')
Сравнение длины ответов на интервью
import re import matplotlib.pyplot as plt
Функция для загрузки текста из файла
def load_text (file_path): with open (file_path, encoding='utf-8', errors='ignore') as f: return f.read ()
Функция для извлечения ответов между знаками вопроса
def extract_answers_between_questions (text): # Находим все фразы между знаками вопроса answers = re.split (r'? ', text) # Разделяем текст на части по знакам вопроса answers = [answer.strip () for answer in answers if answer.strip ()] # Убираем пустые строки
return answers
Функция для подсчёта длины каждого ответа (количество слов)
def answer_length (answers): lengths = [] for answer in answers: # Разбиваем ответ на слова, используя регулярные выражения words = re.findall (r'\b\w+\b', answer) lengths.append (len (words)) # Считаем количество слов в ответе return lengths
Функция для построения графиков длины ответов
def plot_answer_lengths (interview1_lengths, interview2_lengths, title1, title2): # График для длины ответов интервью 1 plt.figure (figsize=(12, 6))
plt.subplot (1, 2, 1)
plt.plot (range (1, len (interview1_lengths) + 1), interview1_lengths, marker='o', linestyle='-', color='green')
plt.xlabel ('Номер ответа')
plt.ylabel ('Длина ответа (количество слов)')
plt.title (f'{title1} — Длина ответов')
plt.xticks (range (1, len (interview1_lengths) + 1)) # Устанавливаем метки как целые числа
# График для длины ответов интервью 2
plt.subplot (1, 2, 2)
plt.plot (range (1, len (interview2_lengths) + 1), interview2_lengths, marker='o', linestyle='-', color='blue')
plt.xlabel ('Номер ответа')
plt.ylabel ('Длина ответа (количество слов)')
plt.title (f'{title2} — Длина ответов')
plt.xticks (range (1, len (interview2_lengths) + 1)) # Устанавливаем метки как целые числа
# Показать оба графика
plt.tight_layout ()
plt.show ()
Загрузка текста из файлов
interview1_text = load_text ('Inter01.txt') interview2_text = load_text ('Inter22.txt')
Извлекаем ответы между знаками вопроса для каждого интервью
interview1_answers = extract_answers_between_questions (interview1_text) interview2_answers = extract_answers_between_questions (interview2_text)
Получаем длину ответов
interview1_answer_lengths = answer_length (interview1_answers) interview2_answer_lengths = answer_length (interview2_answers)
Строим графики длины ответов
plot_answer_lengths (interview1_answer_lengths, interview2_answer_lengths, 'Интервью 1962', 'Интервью 1972')
Ссылка на файлы



