
KMPLZ. Обучение генеративной нейросети
В качестве идеи было выбрано обучить генеративную нейросеть создавать изображения в стиле рисунков художницы kimplz, по совместительству моей одногруппницы.
В качестве материала для обучения был собран архив из 64 цифровых и традиционных рисунков kimplz.


Итоговая серия















Анализ
Так как чаще всего kimplz рисует именно людей, именно на их рисование и был сделан упор в процессе обучения генеративной нейросети. Художница рисует людей очень выразительными, персонажными. Так, целью проекта было обучить модель так, чтобы, глядя на результаты генерации, сразу узнавался фирменный стиль kimplz.
Итоговая серия представляет собой изображения рисунков людей с позами, композиционными решениями, покрасом и лайном, имитирующими стиль художницы.
Далее для сравнения изображения будут представлены так: слева — работа нейросети, справа — работы kimplz из архива для обучения.
Модели удалось обнаружить особенности отрисовки: лайн с толстым многослойным, чаще всего карандашным штрихом; штриховка и плотное закрашивание теней; «волнистость», свободность линии; покрас пастельного типа, со слоями цвета, накладывающимися друг на друга.
Отдельно интересно отметить то, как модель научилась показывать кудрявые волосы. Как и художница, генеративная нейросеть создаёт гипертрофированные завитки.
Создавая изображения в стиле цифрового рисования, модель использует цветной лайн и «маркерный» стиль покраса: переходы между цветами тени и света не размываются, остаются чёткими, но как бы плавно перетекают друг в друга.
Модель отлично научился копировать стиль рисования лиц. Большие выразительные глаза, вытянутые лица, особенности формы подбородка и носа.
Так же хорошо модель справляется и с маскулинными лицами. Длинный нос, толстые брови, квадратный подбородок.
Из двух примеров выше: примечательно, что в зависимости от типа лица (маскулинное или феминное), превалируют соответствующие эмоции. Так, феминные персонажи у нейросети чаще выглядят невинно или слегка удивлённо, а маскулинные хмурятся.
Код и процесс создания
Кроме исходного кода из курса, никаких более ГенИИ не было использовано.
Для начала были загружены все нужные библиотеки и материалы. Так, обучение и последующая генерация модели проходили с помощью LoRA и Dreambooth. LoRA — это метод настройки вводимых данных, значительно упрощающий использование модели и уменьшающый затрачиваемые ресурсы пользователя. Dreambooth — это технология, способная создавать изображения на основе текстового описания.
На обучение модель принимает изображения одинакового разрешения и размера, поэтому предварительно необходимо было написать функцию обрезки картинок (из собранного архива с оригинальными рисунками) и применить ее на каждом изображении из архива.
Далее необходимо было имплементировать и настроить нейросеть BLIP, которая способна делать выводы о происходящем на изображении. Здесь BLIP распознала объекты на изображениях из архива.
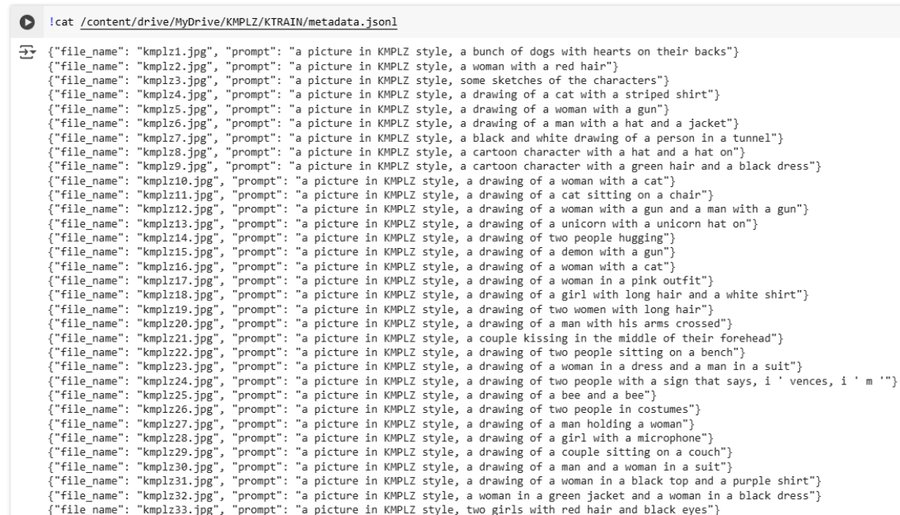

Затем происходило само дообучение модели Stable Diffusion XL с помощью собранных данных. В качестве триггер-слова для модели была задана фраза «KMPLZ»: так, увидев это слово в промпте, модель будет генерирвоать изображения в стиле нужной художницы.
Я поставила 1000 шагов для обучения, чекпойнты которого делались каждые 250 шагов. Так, у меня было бы 4 варианта уровня обучения, которые я могла бы сравнивать.
Всего дообучение заняло 1,5 ч.
Полученную модель я загрузила на HuggingFace.
Затем я пробовала запускать и генерировать изображения с помощью полученной модели через Google Colab.
Мой стандартный промпт выглядел так:
Однако иногда я меняла его значения, чтобы сравнить результаты. Width и height, чтобы регулировать размер изображения; guidance_scale, чтобы управлять тем, насколько свободно модель будет следовать промпту; num_inference_steps, чтобы создавать разный уровень проработки.
Вот, например, один и тот же промпт «KMPLZ, a drawing of a sad girl in a hoodie and jeans» в разных значениях num_inference_steps (20, 50, 70)



")
")

")