
Анализ датасета из kaggle Social Media Usage and Emotional Well-Being
Обосновывая выбор данного датасета, я не постесняюсь признать, что я зависима от соцсетей, мое экранное время составляет более 6 часов, и 80% общих часов я провожу в них… Безусловно, мое психоэмоциональное состояние напрямую связано со всемирной информационной паутиной и при этом я испытываю разные эмоции, и не всегда положительные. Углубляясь в андан, я захотела исследовать этот вопрос конкретнее, на примерах использования социальных сетей другими людьми, то есть на базе данных разных медиа.
Описание датасета: Этот уникальный набор данных был тщательно исследован и подготовлен изобретателем искусственного интеллекта Эмирханом Булутом. Он содержит ценную информацию об использовании социальных медиа и доминирующем эмоциональном состоянии пользователей на основе их действий. Набор данных идеально подходит для изучения взаимосвязи между образцами использования социальных медиа и эмоциональным благополучием.
В датасете данные разбиты на валидационные, тестовые и тренировочные, но так как я не занимаюсь машинным обучением, я буду анализировать на тренировочном датасете, что логично.
Типы созданных графиков: 1.Столбчатый график с интерактивными элементами (библиотека plotly.express) 2.3д график (интерактивный) 3.Violin plot
Этапы работы: 1.Выбор данных, которые интересно проанализировать, предобработка данных 2.Анализ данных 3.Визуализация Оформление графиков: В оформлении графиков я использовала различные стилизации в пастельные цвета, метафора на то, что соцсети для всех, универсальны, также использовала интерактивные элементы, чтобы отразить концепцию соцсетей, что там мы также получаем много информации
Для начала я сделаю общую предобработку (импорт библиотек, поверхностный анализ и тд)

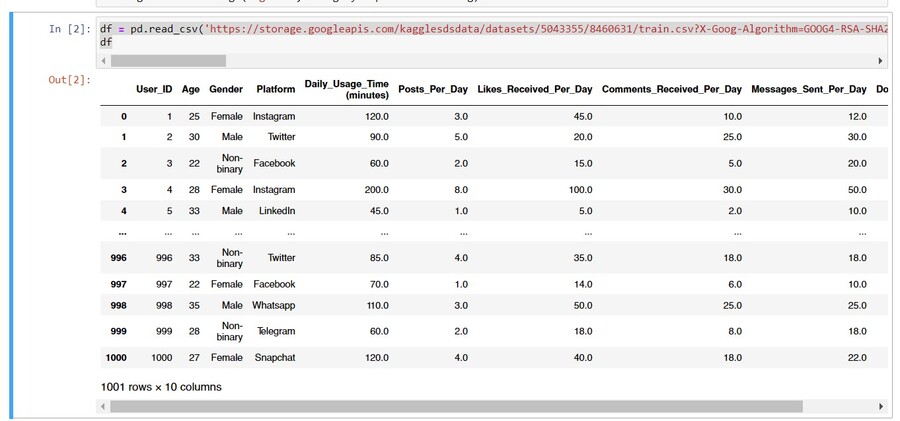
Пропущенных значения есть, посмотрю на уникальные значения в гендере и возрасте, почищу данные еще
Сначала я выбрала для визуализации violin plot, так как группировка данных по категориям (в данном случае социальные сети) позволяет сравнивать распределения между этими категориями на одном графике. Violin plot позволяет визуально сравнивать форму и разброс распределений между различными соцсетями. я попросила ChatGpt «сделать график градиентным, чтобы каждый цвет отражал соцсеть"(промт)
Уже можно смотреть на визуализацию еще зависимости доминирующей эмоции и возраста, попрошу ChatGPT «преобразовать мой код с интерактивной библиотекой plotly и написать код для красивого графика"(промт), использую эту библитотеку, так как можно более наглядно проанализировать данные
Я не всегда ставлю лайки и комментарии пишу довольно редко и мне захотелось посмотреть на корреляцию лайков и комментариев, много ли людей ведут себя подобным образом или преобладающее большинство все-таки чаще высказывается (позитивно или негативно). Для этого использую скеттер график, потому что скопление точек лучше рассматривать для обобщения информации.
На графике выше мы четко видим, что чем реже посты, тем меньше лайков и комментариев, хотя странно, мне бы не хватало времени и желания писать людям комментарии постоянно, скорее вызывало бы раздражение постоянно мелькающие однотипные посты в ленте.
Теперь попробую сгруппировать информацию в единый 3д график, чтобы проследить зависимость времени использования и получения лайков на платформе для дальнейшего анализа. Я использовала как промт в ChatGpt свою строку кода с визуализацией с помощью библиотеки seaborn двух признаков, попросила добавить третий «Platform» и визуализировать с символами, которые будут отличать эмоции. Вот что из этого получилось:


Ссылка на Jupyter Notebook:
Ссылка на проанализированный датасет:
Использованные инструменты:
Обложка проекта создана с использованием https://app.leonardo.ai/
")
")

")