
Визуализация данных о мемах c Reddit
Выбор данных для анализа

Я очень люблю мемы. Именно поэтому я выбрала эту тему для анализа. Тем более, простые и смешные картинки могут сказать гораздо больше, чем кажется на первый взгляд: предпочтения людей, их мировоззрение, мнения, взгляды.
На сайте kaggle.com я нашла датасет Memotion Dataset 7k, из которого брала информацию.
Стиль
Один из самых узнаваемых мемов — лягушка Пепе. В честь Пепе в качестве цветовой палитры я использую градацию зеленого цвета.

Анализ текста
Я подумала, что анализ мемов стоит проводить в несколько разделов. Первый — текст. Он задает характер повествования, доносит мысль и является основополагающим элементом.
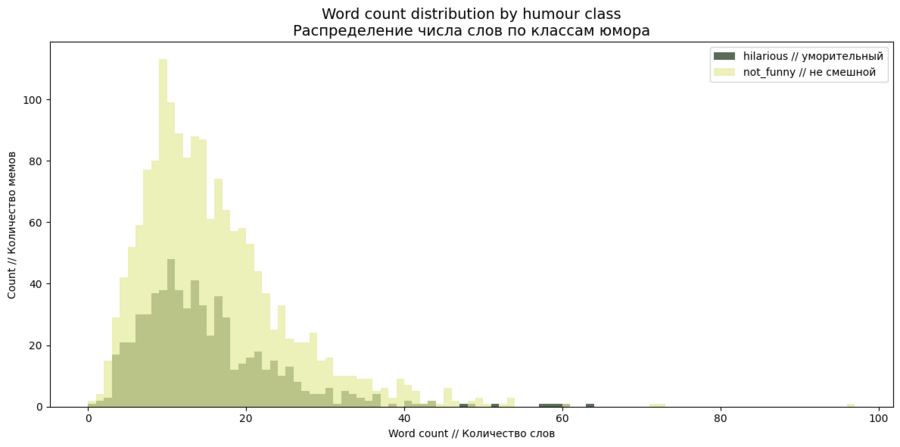
Первый анализ — взаимосвязь количества слов и «уровня» мемов. Зависит ли то, насколько смешной мем, от количества слов в его тексте? Чаще происходит так, что чем меньше слов — тем картинка смешнее.

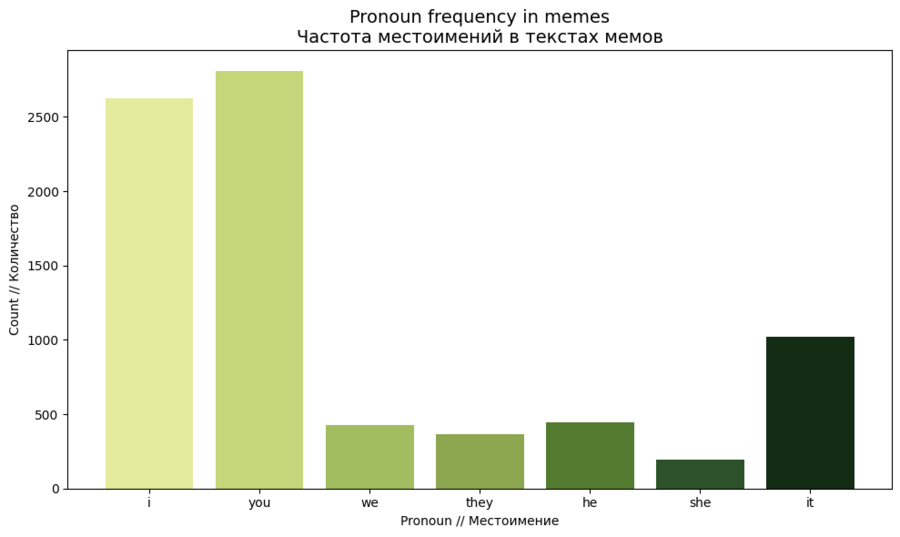
Большая часть мемов строится вокруг личного опыта («you», «I») и типичных мемных конструкций («when you», «i can’t»), что подчёркивает разговорный характер мемного языка.

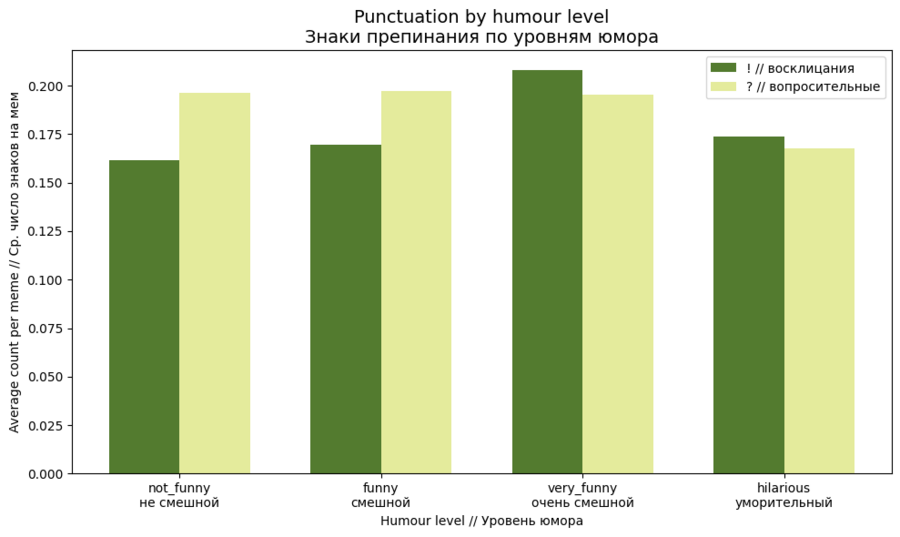
Была построена столбчатая диаграмма соотношения кол-ва знаков препинания и уровня юмора мемов. Для этого были использованы классификации юмора: not_funny, funny, very_funny, hilarious.

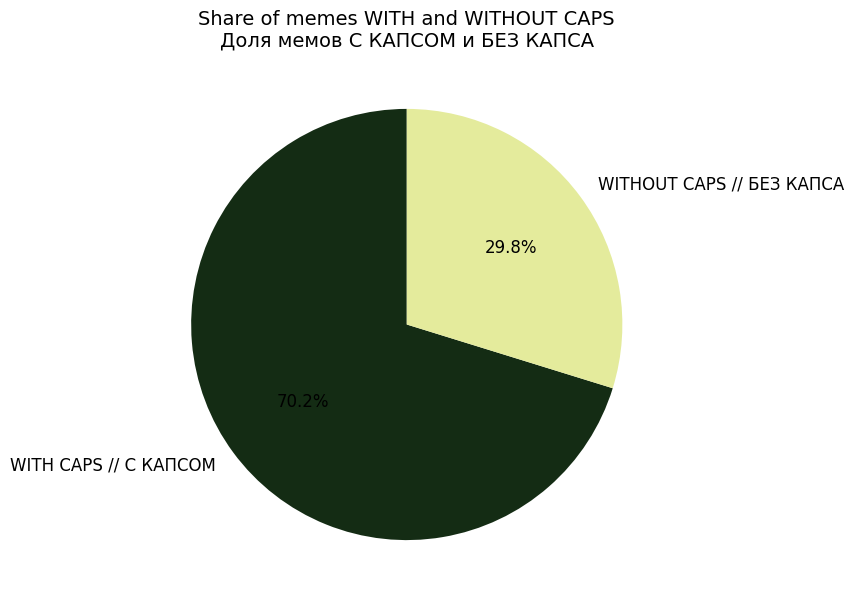
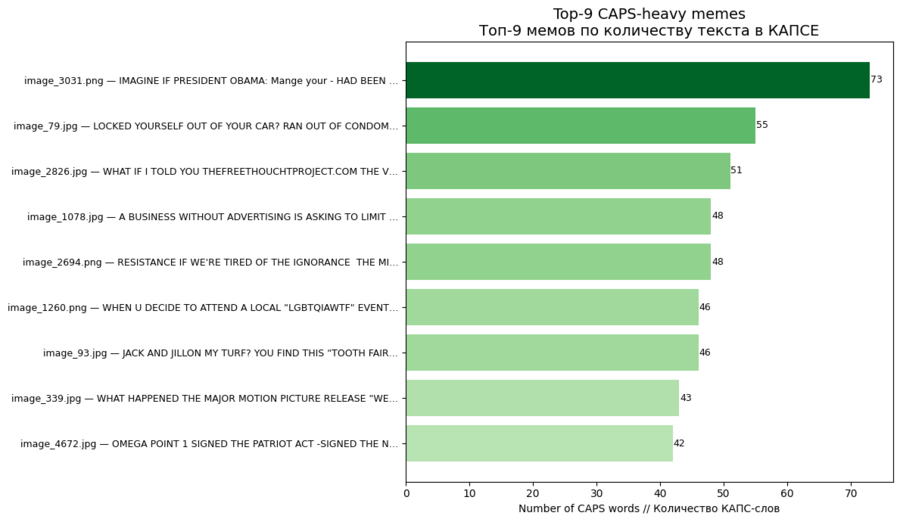
После этого был построен круговой график на анализ соотношения доли мемов, где используются только заглавные буквы (капс), и где не используются.
Также было создано облако слов с наиболее часто использованными словами в мемах с текстовой составляющей.


По структуре текста заметно, что большинство мемов используют короткие, простые слова и предложения. Однако в самых смешных и самых саркастичных мемах средняя длина слов выше, это указывает на более насыщенный и «умный» стиль подачи. Анализ пунктуации показывает, что эмоциональность выражается главным образом через восклицания и CAPS LOCK, который часто встречается в условиях высокой интенсивности юмора или токсичности.
Анализ характера мемов
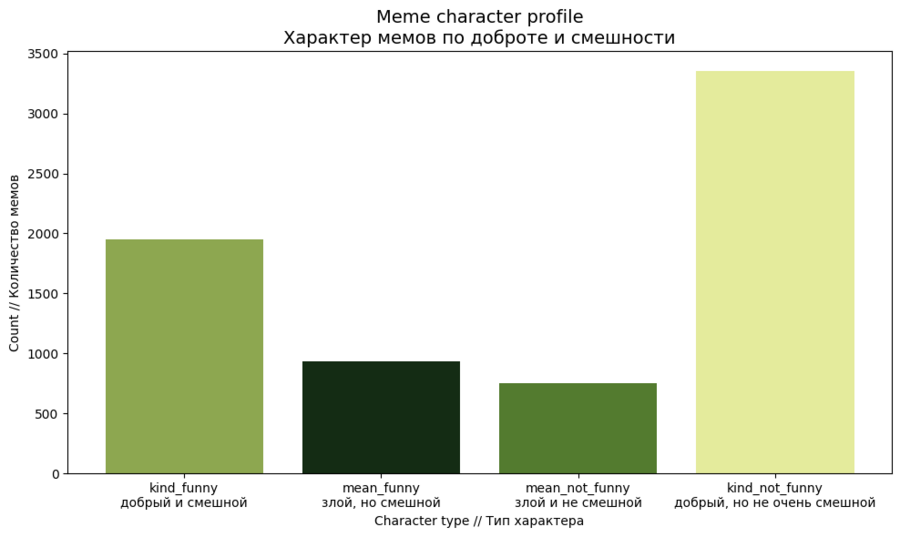
Далее я провела анализ мемов по их характеру: мемы могут быть весёлыми, оскорбительными, нейтральными, добрыми и тд.
Каждую характеристику я перевела с английского (из датасета) на русский язык, но с сохранением оригинального названия параметра.
Судя по анализу и первому столбчатому графику в этом разделе, юмор гораздо чаще возникает в позитивном или нейтральном тоне, а попытки сделать «злой юмор» встречаются реже.

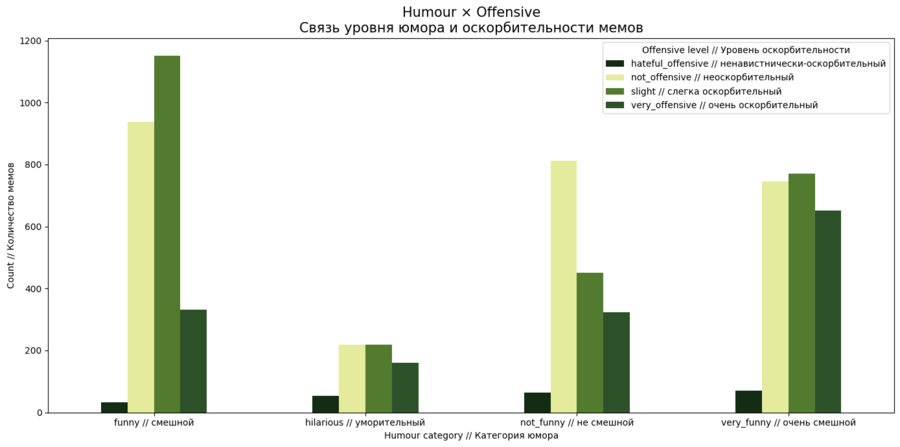
Распределение оскорбительности существенно различается между категориями юмора. Наиболее заметно, что в группе funny значительную долю составляют неоскорбительные и слегка оскорбительные примеры. Это означает, что умеренный юмор чаще всего подаётся в относительно мягкой форме.
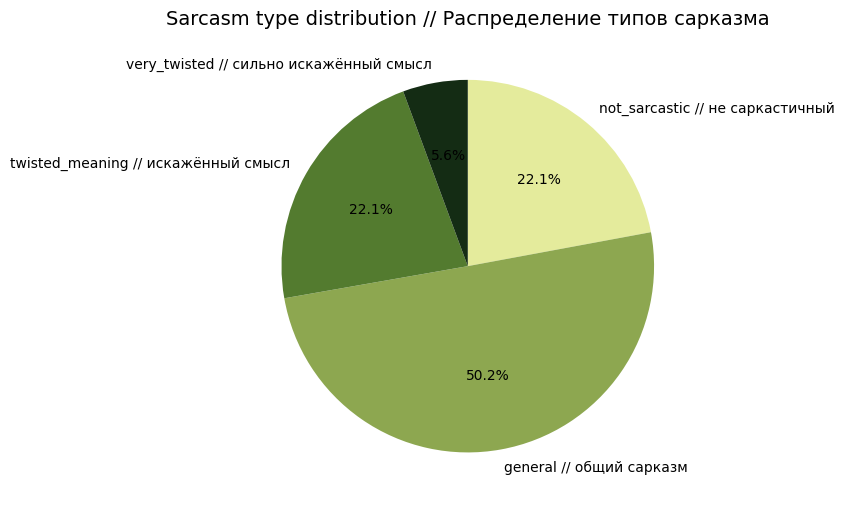
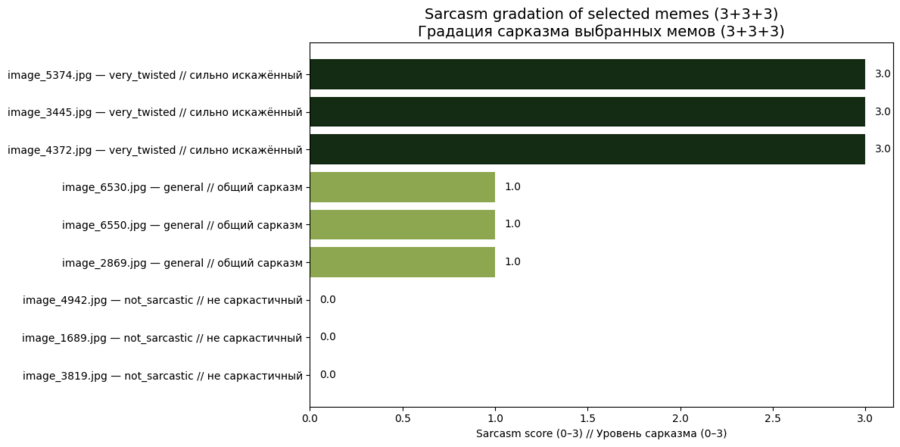
Большинство мемов используют мягкую, универсальную форму сарказма, встречающуюся в повседневной интернет-коммуникации.

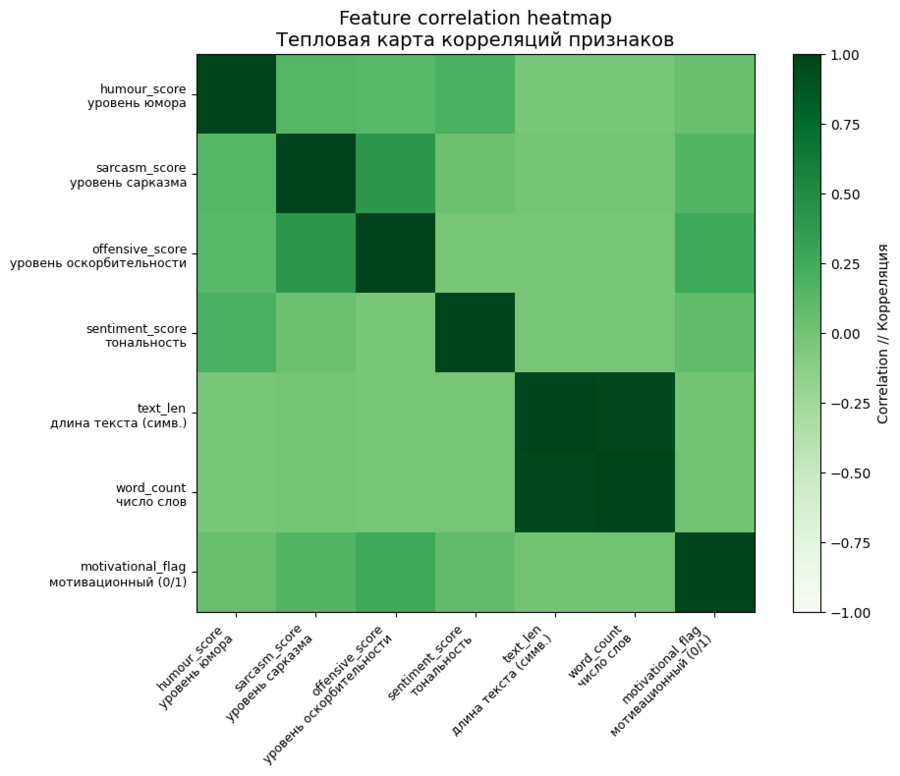
Тепловая карта показывает, что большинство текстовых и смысловых характеристик мемов слабо коррелируют друг с другом. То, насколько мем смешной, не объясняется напрямую ни его тональностью, ни саркастичностью, ни токсичностью.

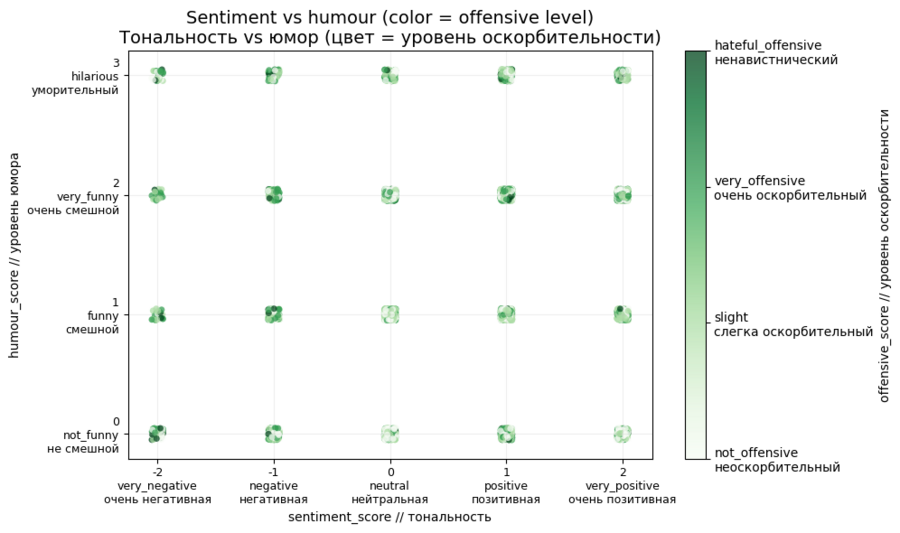
Юмор и тональность в мемах распределяются довольно хаотично и не образуют выраженной линейной зависимости: смешные мемы встречаются как среди позитивных, так и среди негативных сообщений.

Эмоциональный анализ текста показывает доминирование позитивных эмоций (joy, anticipation), но при этом есть и заметный слой негативных эмоций (anger, sadness), что отражает разнообразие тем и тонов.
Топ мемов по разным характеристикам
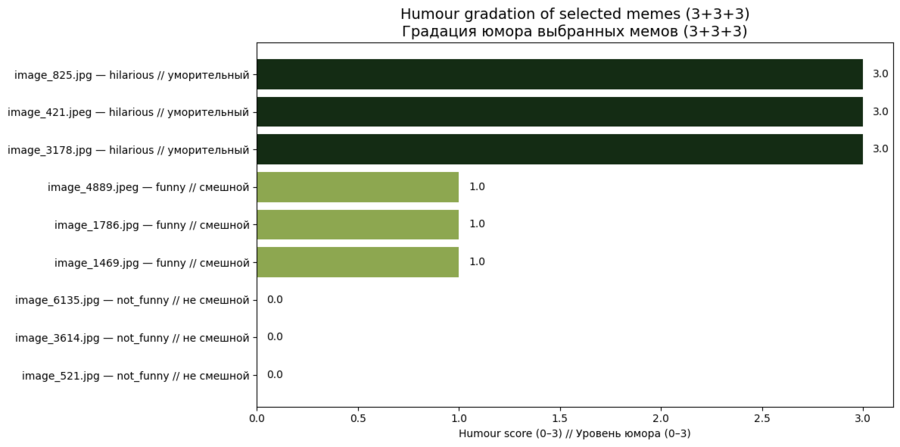
Далее мне захотелось визуализировать датасет. Например, отобрать топ мемов по какой-либо характеристике (сарказм, оскорбительность, весёлость), взять из каждой группы (от 1 до 3 по силе характеристики) по несколько примеров и показать и график, и мемы, которые в нём находятся.



Заключение
В целом, мемы в датасете демонстрируют комбинацию простоты текста, высокой эмоциональности и разнообразных коммуникативных стратегий.
Описание применения генеративной модели
В проекте использовались нейросети ChatGPT и DeepSeek для генерации кода и для помощи в анализе данных.
Иллюстрации были созданы с помощью ChatGPT.



