
Анализ лауреатов премии «Оскар»
Концепция
Анализ данных о лауреатах премии «Оскар» позволяет выявить ряд интересных тенденций и закономерностей, отражающих как социокультурные изменения, так и эволюцию кинематографа. Доминирование определенной расы и гендерный дисбаланс постепенно сменяются более инклюзивным подходом. Возрастные особенности лауреатов в разных категориях наград свидетельствуют о различных требованиях к опыту и мастерству.


Премия «Оскар» — одно из самых престижных событий в мире кино. Анализ данных о лауреатах позволяет выявить интересные закономерности и тенденции в предпочтениях Киноакадемии и проследить эволюцию кинематографа. Жанры фильмов-победителей отражают социокультурные изменения и интересы общества.
Для анализа были выбраны данные о лауреатах премии с 1929 по 2016 год, найденные на платформе Kaggle.
Для анализа было выбрано 5 видов графиков: Столбчатые диаграммы, для наглядного сравнения количества лауреатов в разных категориях; круговые диаграммы, для отображения процентного соотношения различных категорий внутри целого; графики областей, для отображения динамики изменения расового состава победителей во времени; линейный график, для отображения разрывов в гендерном отношении победителей во времени и график-скрипка, для визуализации распределения возраста лауреатов в различных номинациях.
Обработка данных
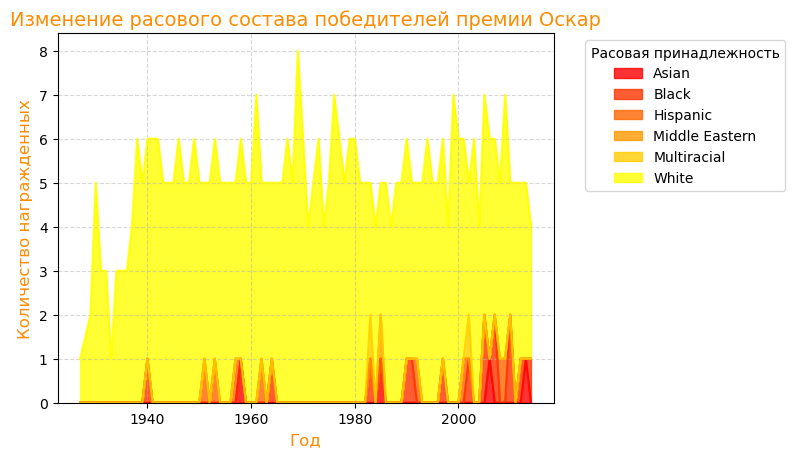
Изменение расового состава победителей премии Оскар
import matplotlib.pyplot as plt и import pandas as pd: Импортируем необходимые библиотеки.
file_path = r"C:\Users\kate\Downloads\Oscars-demographics-DFE.csv»: Указываем путь к файлу с данными.
df = pd.read_csv (file_path, encoding="latin1»): Читаем CSV-файл с помощью Pandas в DataFrame df. encoding="latin1»
df_race = df[[«year_of_award», «race_ethnicity»]].dropna (): Создаем новый DataFrame df_race, содержащий только столбцы «year_of_award» и «race_ethnicity», и удаляем строки с пропущенными значениями (NaN).
df_race_grouped = df_race.groupby ([«year_of_award», «race_ethnicity»]).size ().unstack ().fillna (0): Группируем данные по «year_of_award» и «race_ethnicity», считаем количество записей в каждой группе (.size ()), затем «раскрываем» таблицу, чтобы «race_ethnicity» стали столбцами (.unstack ()), и заполняем пропущенные значения нулями (.fillna (0)).
plt.figure (figsize=(12, 6)): Создаем новую фигуру для графика с размером 12×6 дюймов.
df_race_grouped.plot (kind="area», stacked=True, colormap="autumn», alpha=0.8): Строим график типа «area» (с областями), где области складываются друг над другом (stacked=True), используем цветовую карту «autumn» и устанавливаем прозрачность alpha=0.8.
plt.title (…), plt.xlabel (…), plt.ylabel (…): Устанавливаем заголовок графика, подписи осей и настраиваем их внешний вид.
plt.grid (True, linestyle="--», alpha=0.5): Включаем отображение сетки.
plt.legend (…): Отображаем легенду и настраиваем ее положение.
plt.show (): Отображаем график.
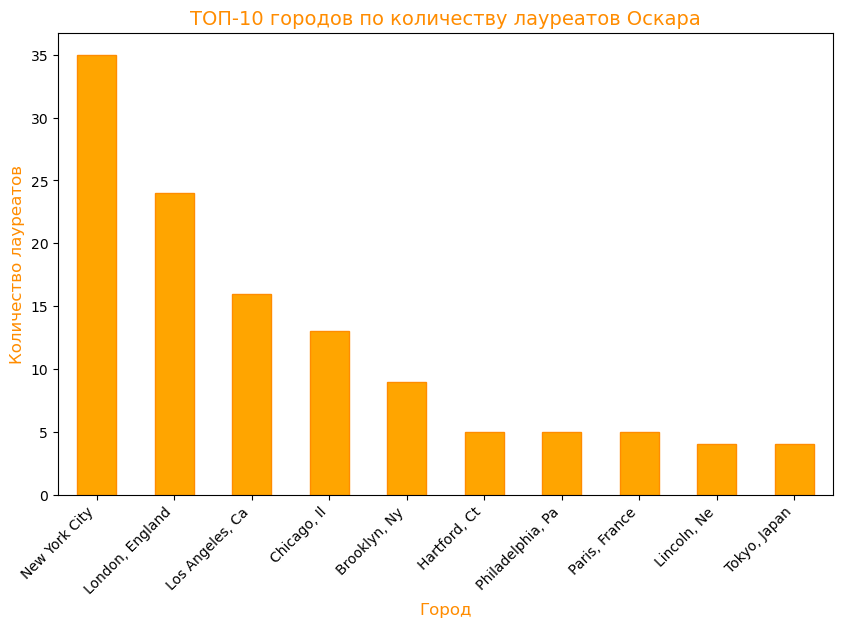
ТОП-10 городов по количеству лауреатов Оскара
df_cities = df[[«birthplace»]].dropna (): Создаем новый DataFrame df_cities, содержащий только столбец «birthplace», и удаляем строки с пропущенными значениями.
city_counts = df_cities[«birthplace»].value_counts (): Считаем количество упоминаний каждого города в столбце «birthplace».
top_cities = city_counts.head (10): Выбираем 10 городов с наибольшим количеством упоминаний.
plt.figure (figsize=(10, 6)): Создаем новую фигуру для графика.
top_cities.plot (kind="bar», color="orange», edgecolor="darkorange»): Строим столбчатую диаграмму для 10 городов.
plt.title (…), plt.xlabel (…), plt.ylabel (…): Устанавливаем заголовок графика и подписи осей.
plt.xticks (rotation=45, ha="right»): Поворачиваем подписи по оси X на 45 градусов для удобства чтения.
plt.show (): Отображаем график.
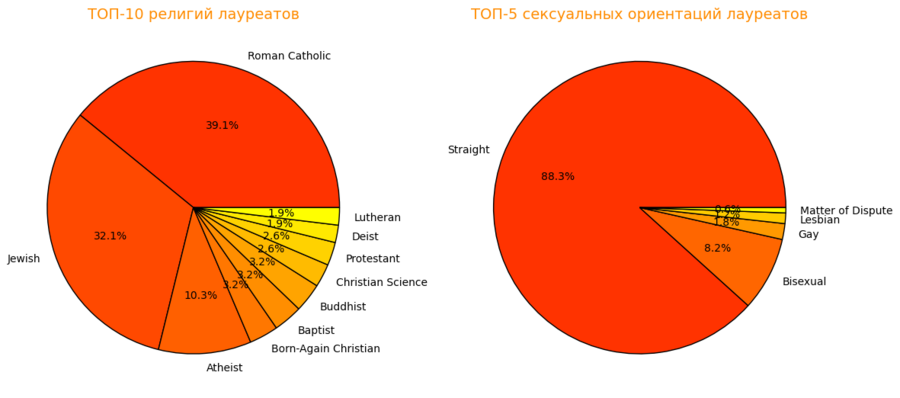
ТОП-10 религий и сексуальных ориентаций лауреатов
df_clean = df[[«sexual_orientation», «religion»]].dropna (): Создаем DataFrame с двумя столбцами и удаляем строки с NaN.
df_clean = df_clean[(df_clean[«sexual_orientation»] ≠ «Na») & (df_clean[«religion»] ≠ «Na»)]: Удаляем строки, где «sexual_orientation» или «religion» равны «Na».
df_pie_religion = df_clean[«religion»].value_counts ().head (10): Считаем кол-во каждой религии и берем первые 10.
df_pie_orientation = df_clean[«sexual_orientation»].value_counts ().head (5): Считаем кол-во каждой ориентации и берем первые 5.
plt.subplot (1, 2, 1) и plt.subplot (1, 2, 2): Создаем два подграфика в одной фигуре.
df_pie_religion.plot (kind="pie», …) и df_pie_orientation.plot (kind="pie», …): Строим круговые диаграммы с настройками внешнего вида.
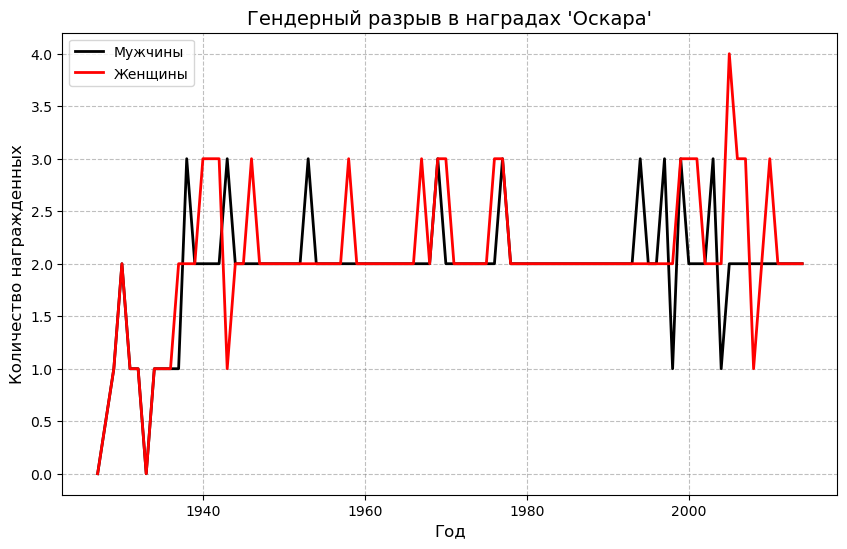
Гендерный разрыв в наградах Оскар
df[«gender»] = df[«award»].apply (lambda x: «Male» if «Actor» in x else «Female» if «Actress» in x else «Unknown»): Создаем новый столбец «gender» на основе столбца «award». Если в названии награды есть «Actor», то пол — «Male», если «Actress» — «Female», иначе — «Unknown». Это упрощенный подход, но для нашей задачи подходит.
df_gender_trend = df.groupby ([«year_of_award», «gender»]).size ().unstack ().fillna (0): Группируем данные по году и полу, считаем количество записей в каждой группе, «раскрываем» таблицу, и заполняем пропущенные значения нулями.
plt.plot (…): Строим линейные графики для мужчин и женщин.
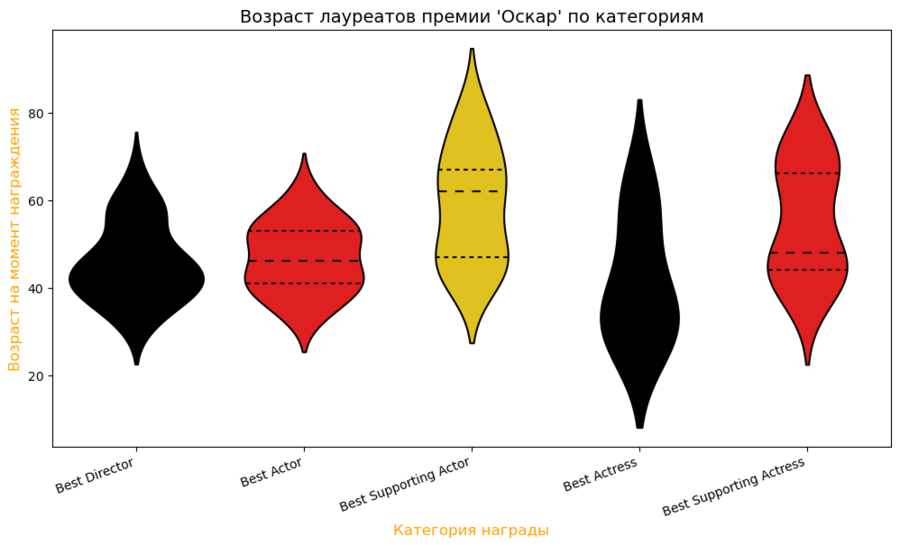
Возраст лауреатов премии по категориям
df['age_at_award'] = df['year_of_award'] — df['year_of_birth']: Вычисляем возраст на момент награждения.
df_filtered = df[(df['age_at_award'] >= 18) & (df['age_at_award'] <= 100)]: Фильтруем данные, оставляя только записи, где возраст на момент награждения находится в диапазоне от 18 до 100 лет.
main_categories = […] и df_filtered = …: Оставляем только записи для основных категорий наград.
sns.violinplot (…): Строим график-скрипку с использованием библиотеки Seaborn.
Заключение
Проведенный анализ данных о лауреатах премии «Оскар» выявил ряд значимых и интересных тенденций, отражающих динамику мира кино и общества. Премия постепенно становится более инклюзивной, приветствуя разнообразие талантов и историй. Закономерности в возрасте победителей разных категорий подчеркивают ценность как молодого энтузиазма, так и зрелого мастерства. Это исследование дает ценный взгляд на эволюцию премии и подтверждает его роль как зеркала, отражающего культурные изменения и достижения кинематографа.
Описание применения генеративной модели
Для работы были использованы изображения, сгенерированные в Ideogram
Промпты: (1) Generate data visualization overlayed on a red carpet background, golden numbers and chart elements, elegant typography, text «Oscar Genre Analytics», modern and clean style, 16:9
(2-3) Generate golden Oscar statuette surrounded by film reels and film strips, colors in gold, orange, and red, cinematic lighting, elegant typography, text «Genre Trends at the Oscars», data visualization elements, 16:9
Ссылка на модель: https://ideogram.ai/
Блокнот и датасет



