
Такси в NYC
Мой проект по применению программирования в креативных индустриях посвящен анализу данных о такси в Нью-Йорке.
Такси — неотъемлемая часть крупных и динамичных городов во всем мире, так как этот вид транспортных услуг экономит много времени и сил. Исследование данных такси мне показалось интересно тем, что уникальные маршруты и поездки людей в одном из самых насыщенных по ритму жизни городов планеты могут позволить визуализировать Нью-Йорк как целую живую и неравномерную систему, узнать особенности и контрасты районов, а также отразить реальную городскую среду.
Для визуализации данных я планирую использовать следующие типы графиков: 1. Геопространственная карта плотности (хлороплентная) 2. Столбчатая диаграмма 3. Пузырьковая диаграмма 4. Линейный график 5. График распределения
Стилизация визуала

Для работы я импортировала библиотеки pandas и numpy для анализа данных, geopandas для работы с географией, folium и branca.colormap для создания интерактивной карты, matplotlib для построения графиков, а также csv-файл с информацией о поездках такси. Дополнительно использова json с границами зон такси Нью-Йорка.
import numpy as np import pandas as pd import geopandas as gpd import folium from branca.colormap import linear import matplotlib.pyplot as plt import json
df = pd.read_csv («taxi_tripdata.csv») zones = gpd.read_file («NYC Taxi Zones.geojson»)
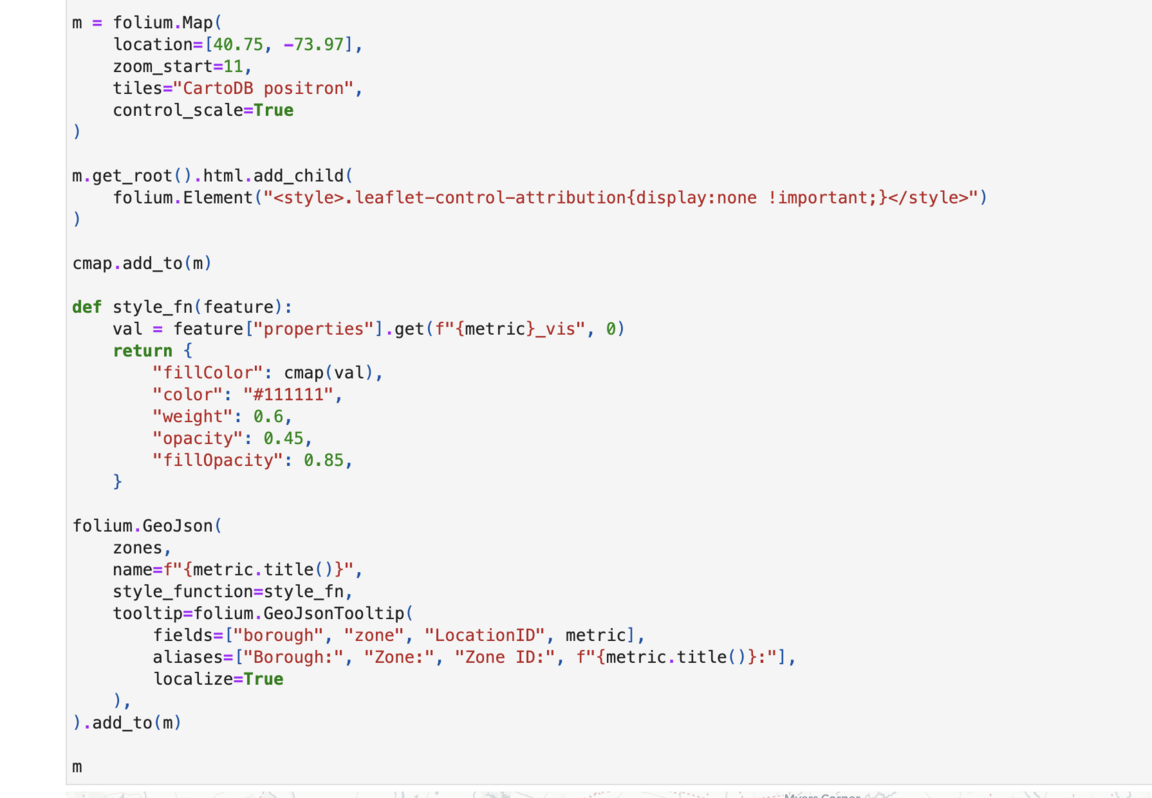
1. Интерактивная карта интенсивности поездок
Сначала я обобщила данные о поездках по зонам посадки пассажиров, и для каждой из них было подсчитано количество поездок такси.
pickups = df.groupby («pulocationid»).size ().reset_index (name="pickups»)
Затем я объединила данные о количестве поездок с географическими данными зон города, а для улучшения визуального восприятия я ограничила экстремальные значения и применила логарифмическое преобразование.
p99 = zones[«pickups»].quantile (0.99) zones[«pickups_vis»] = np.log1p (zones[«pickups»].clip (0, p99))
После этого я построила интерактивную карту, где цвет зоны показывает интенсивность поездок.
folium.GeoJson ( zones, style_function=style_fn, tooltip=folium.GeoJsonTooltip (fields=[«borough», «zone», «pickups»]) ).add_to (m)
Код для анализа датасета и создания карты
Код для аналитической визуализации
2. Столбчатая диаграмма
Чтобы понять, в каких районах такси используют чаще всего, я сгруппировала поездки по боро и посчитала их количество.
counts = df[«borough»].value_counts ()
Затем я задала порядок районов, чтобы диаграмма выглядела логично.
counts = counts.reindex ([«Manhattan», «Brooklyn», «Queens», «Bronx», «Staten Island»])
После этого я построила столбчатую диаграмму, где каждый столбец является отдельным районом города.
ax.bar (counts.index, counts.values, color=colors)


Код для анализа датасета и создания столбчатой диаграммы
3. Пузырьковая диаграмма
Сначала я рассчитала длительность каждой поездки в минутах.
df[«duration_min»] = (df[dropoff] — df[pickup]).dt.total_seconds () / 60
Потом я объединила данные по боро и посчитала типичную дистанцию, медианную длительность и количество поездок.
agg = df.groupby («borough»).agg ( trips=(«borough», «size»), med_distance=(«distance_miles», «median»), med_duration=(«duration_min», «median»)
На основе этих данных я сделала пузырьковую диаграмму, где положение пузыря показывает типичную поездку, а его размер соотвествует популярности такси в районе.
ax.scatter (agg[«med_distance»], agg[«med_duration»], s=agg[«bubble»])


Код для анализа датасета и создания пузырьковой диаграммы
4. Линейный график
Чтобы посмотреть, как меняется спрос на такси в течение суток, я выделила час посадки из времени поездки.
tmp[«hour»] = tmp[pickup].dt.hour
Дальше я посчитала количество поездок по часам и боро и немного упростила значения.
hourly = tmp.groupby ([«hour», «borough»]).size ().reset_index (name="trips») hourly[«trips_smooth»] = hourly.groupby («borough»)[«trips»].rolling (3, center=True).mean ()
После этого я построила линейный график, который показывает, в какое время суток такси используют чаще всего в разных районах.
ax.plot (d[«hour»], d[«trips_smooth»])
Код для анализа датасета и создания линейного графика
5. График распределения
Для анализа длины поездок я задала интервалы дистанций.
bins = np.linspace (0, 30, 61)
Затем я посчитала распределение дистанций поездок для каждого боро.
hist, _ = np.histogram (d, bins=bins) dens = hist / hist.sum ()
После этого я построила график распределений, который показывает, где чаще встречаются короткие и длинные поездки.
ax.plot (centers, dens)
Код для анализа датасета и создания графика распределения
В рамках данного проекта был проведен анализ данных о такси в Нью-Йорке, который позволил изучить ключевую информацию по теме. Благодаря использованию современных методов анализа данных и визуализации, удалось ответить на ряд важных вопросов о районах, загруженности и особенностях маршрутов.
В проекте была использована нейросеть ChatGPT с целью проверки кода и объяснения, как создать нетипичиную интерактивную карту (график первый), а также для генерации обложки



