
Анализ данных в анимационных фильмах о привычках
В современном мире, где информация постоянно поступает из самых разных источников, особенно важно уметь критически оценивать и анализировать то, что мы слышим и читаем. Это особенно верно в отношении вопросов здоровья и образа жизни, где существует множество противоречивых мнений и утверждений.
В рамках данного исследования я решила проанализировать две видео-транскрипции с популярного видеохостинга YouTube, посвященные теме вредных и полезных привычек. Меня заинтересовало, с какой стороны авторы подходят к тому или иному образу жизни, что они стараются донести и о чем говорят больше — о пользе или о вреде для жизни.


Изображения сгенерированные с помощью ИИ (Fast Stable Diffusion XL on TPU v5e)


Указание ссылок на видео в YouTube

Используется библиотека PyTube для скачивания видео:
Взяв за основу два противоположных ролика о Вредных и Полезных привычках, с помощью кода на языке Python, нейросеть OpenAI Whisper проанализировала полный хронометраж поучительных видео и выдала два текстовых файла с расшифрованной речью на английском языке.
Запустив команду whisper, которой необходимо передать имя звукового файла для распознавания, мы получает транскрипцию в текстовом формате. Это упрощает расшифровку видео и уменьшает временные затраты на транскрипцию вслед за диктором.
Whisper содержит несколько моделей. По умолчанию используется небольшая модель, дающая оптимальное сочетание по скорости и качеству распознавания. Чтобы повысить качество распознавания, можно передать в команду параметр --model large.v3, это может немного повысить качество, но при этом существенно замедлит скорость распознавания.


Транскрипция на английском языке первого видео о Полезных привычках

Транскрипция на английском языке второго видео о Вредных привычках
Подсчитываем ключевые слова
Опишем функцию для подсчета частотного словаря текстового файла. На этот раз для обработки текста и разбиения его на слова будем использовать библиотеку работы с естественным языком NLTK (Natural Language Toolkit). Для начала, разбиваем текст на слова, игнорируя знаки препинания
Построив частотный словарь, не добавляем называемые стоп-слова — это часто-употребляемые слова, наподобие and, or и т. д. В NLTK уже есть список стоп-слов для английского языка.
Получив огромное множество слов с количеством упоминаний в видео — создадим функцию для нахождения наиболее часто употребляемых слов
Самые часто используемые слова:
Программа выдает список наиболее часто употребляемых слов, с которыми теперь можно работать визуально
Данные в виде графиков
На примере данного кода в графики вносятся данные о часто употребляемых словах в видео о полезных и вредных привычках — указана их частота от меньшего к большему
данные о часто употребляемых словах в видео о полезных и вредных привычках
Анализируя получившиеся таблицы, можно и вправду сказать, что в видео о полезных привычках большое количество времени уделено разговору о лучшем образе жизни для человека, о необходимости соблюдения рутины и временного плана — однако второе слово «BAD» , свидетельствует о наличии разграничений на черное и белое в видео, которое к этому не относится. В статистике о вредных привычках по получившимся данным, можно говорить о наличии информации по теме привычек, связанных с нездоровым образом жизни.
Если сконцентрироваться отдельно только на позитивных словах, работая со словарём позитивных и негативных слов: можно описать функцию извлечения топ-слов по частоте, которые при этом входят в заданное множество wset. При этом будем возвращать относительную частоту слова, т. е. число его вхождений, делённое на общую длину словаря. Так мы сможем сравнивать значения частоты для разных по длине текстов и изображать это наглядно на графике.
Загрузка библиотек с позитивными и негативными словами для анализа
Превратим полученную информацию в графики для наглядного анализа
Графики, полученные на основе словарей позитивных слов, которые встречаются и в видео о полезных привычках, и в видео о плохих привычках
Таким образом в обоих видео наглядно видно частое употребление позитивных слов, что говорит о мотивирующем настрое первого видео и о наличии морали во втором.
Проводя эксперимент с полученными данными, я получила процент всех позитивных слов в тексте, предварительно создав таблицу, чтобы исходя из нее создать круговые диаграммы:

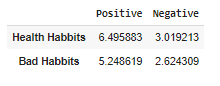
Код, выводящий полученные данные из таблицы в диаграммы
Выводы
Исследование показало, что видеоролики, предназначенные для освещения как позитивных, так и негативных последствий определенного поведения, одинаково эффективны в побуждении людей к положительным изменениям. Это означает, что независимо от того, сосредоточены ли видеоролики на потенциальных выгодах хорошего поведения или риске плохого поведения, они могут эффективно мотивировать людей к достижению более высоких целей. Этот вывод имеет важные последствия для формирования общественного здравоохранения и разработки образовательных кампаний, поскольку он предполагает, что акцент может быть сделан как на положительных, так и на отрицательных последствиях для достижения желаемого эффекта поведения.
В пользу использования нейросетей можно сделать вывод, что их использование для автоматизации задач обработки данных, таких как очистка, преобразование и нормализация данных — освобождает исследователей от трудоемких ручных процессов, позволяя им сосредоточиться на анализе и интерпретации данных.
Изображение, сгенерированное с помощью ИИ (DALL•E 3 XL v2)
Проект в Google Collab: https://colab.research.google.com/drive/1foNiuWmyFsJ5001WT-sPV-G5pnZECW1I?usp=sharing
Использованные нейросети и ресурсы: DALLE 3 XL v2 — a Hugging Face Space by ehristoforu: https://huggingface.co/spaces/ehristoforu/dalle-3-xl-lora-v2
Stable Diffusion XL on TPUv5e — a Hugging Face Space by google: https://huggingface.co/spaces/google/sdxl
GPT-OPEN — Онлайн чат с искусственным интеллектом GPT: https://gpt-open.ru/
GPT3.5-Chatbot: https://thechatgpt.ai/ru/chat
Видео ресурсы: https://youtu.be/wr6fQ4KpbRM?si=No8JoXAzSDDeXcXF https://youtu.be/C07DdQbnFMs?si=q_-YHwAcL7uK0ci3



