
Project idea
When I was eight years old, I was given a large blue snake, a soft toy. I named him Kudav. Since then, it’s my favorite childhood toy, and I’ve decided that it needs to be permanent in digital space so that it can always be around. To implement this idea, I have decided to use the technology of learning the generic neuronet of Stable Diffusion so that it can accurately create different images with Kudav.
Why Kovad is a unique and unique subject for neuronet education

Photo by Kudawa
Although Kudav looks like an ordinary blue toy snake, he has several features. First of all, he has dark blue spots on his back, second of all, once after washing, his tongue suddenly split, and now he lives with two languages. Third, once again, after the laundry, Dad hung his non-wedding ropes to dry, but the filler inside Kodava was knocked down by dividing the snake’s body into pieces. Now it can be unnatural to pull it off.
Model learning process
To learn neuronets, you need a dataset with images of Kudad. I did a little photo shoot for him, and then I scrubbed all the images to 1:1 and manually reduced them to 1024×1024 pixels. When I created the photo, I tried to show Kudava in different positions, but I kept the focus on his unique face. As a result, 76 photos of the snake were collected on the dataset.
Examples of Kudawa photos on the dataset
part of the dataset collected
[ Shag 1 ] Next, I moved to the Kaggle programming environment, and I imported a source laptop with a code for the «Stable Diffusion XL» in LoRA technology. Then she connected the GPU P100 accelerator and connected the laptop to the Internet. Next step, I installed all the necessary libraries — bitsandbytes and diffusers, as well as a special script for model learning.
Preparation for model training
[ Shag 2 ] At this stage, I’m, first, downloading the collected dataset with Kudav to Kaggle and checking if it’s properly loaded. Second of all, I’m building a directory, and I’m copying all the dataset files there, and I’m rechecking again that everything works right.
Establishment of a directory
It’s working!! Hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey, hey.
[ Shag 3 ] Then I generate prompts to the pictures so I can neuralize what’s in the photo. To that end, I download the BLIP model and launch the Caption_images function, which describes and describes every picture of Kudawa from the dataset. Everything is recorded in the variable imgs_and_paths, where this list of images with signatures is created. The list is then collected in a file, where every signature is now accompanied by a photo of KUDAV snake, which is responsible for ensuring that the model then refers specifically to Kudava when producing its images. At the end, I remove this model from memory to make room.
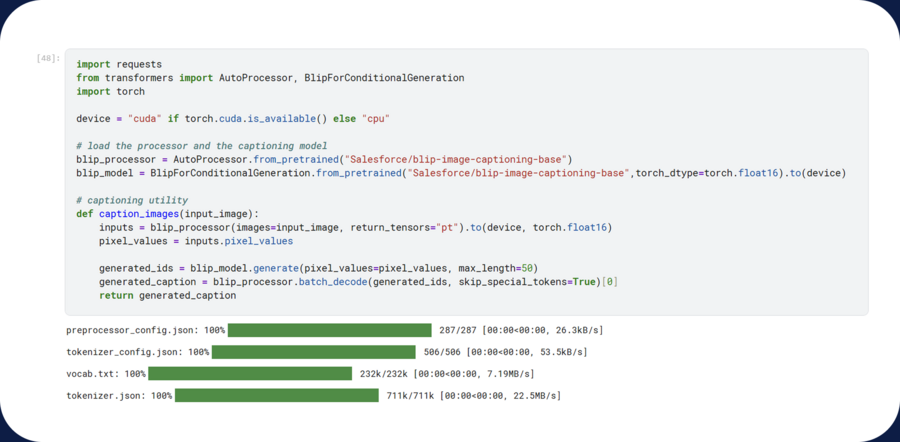
BLIP image creation process
Example of outcome 3 steps
[ Shag 4 ] At this stage, the script accelerate needs to be initialized so that the model can eventually be saved on the Hugging Face portal. Next on this portal, I created a recording and reading current that entered into the code box on the laptop, and you can start learning.
Hugging Face connection
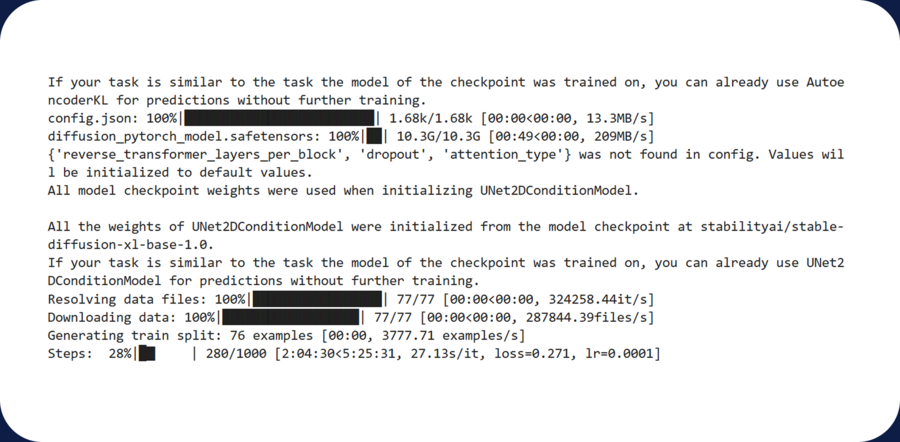
[ Shag 5 ] Before launching the training, it is necessary to install a dataset library and then set the parameters on the accelerate command: the name of the dateset is kudav, the directory with the model is kudav_snake_LoRA, and the code mark is a photo of KUDAV snake. In the first version of the training, I put 1024 as my photo, with the maximum number of steps, 1,000 and 512 with a checkpoint. The whole learning process was supposed to take about seven hours, but, unfortunately, after five hours of model operation, I had to start again. For the second time, I started training already in resolution 512, the total number of steps also in 1,000 and in cuppets after every 125 steps so that you could see how the model is being taught at different stages. But my laptop was full-on, so I’ve made a lot of efforts to teach neurosmart. As a result, I had a 512 resolution with 500 steps, and it took about an hour to learn the model.
Installation of datasets library
Model learning parameters
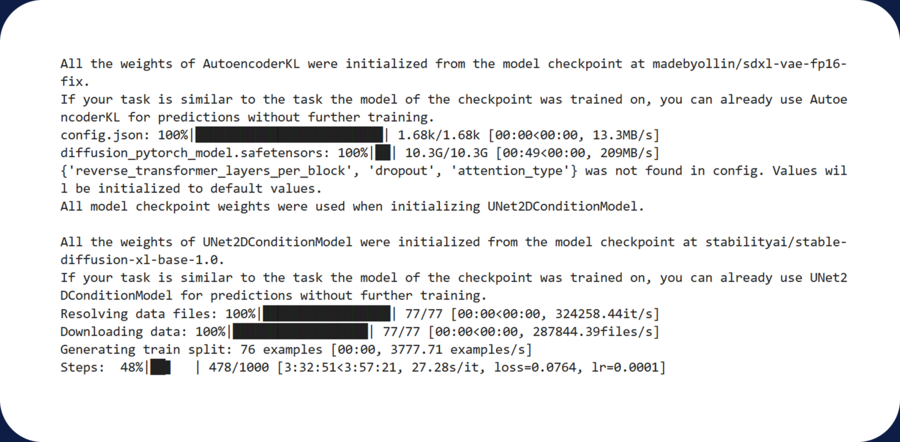
First attempt (disrupted)
Learning process during second — first attempts
Outcome parameters
Checking the directory with a trained model.
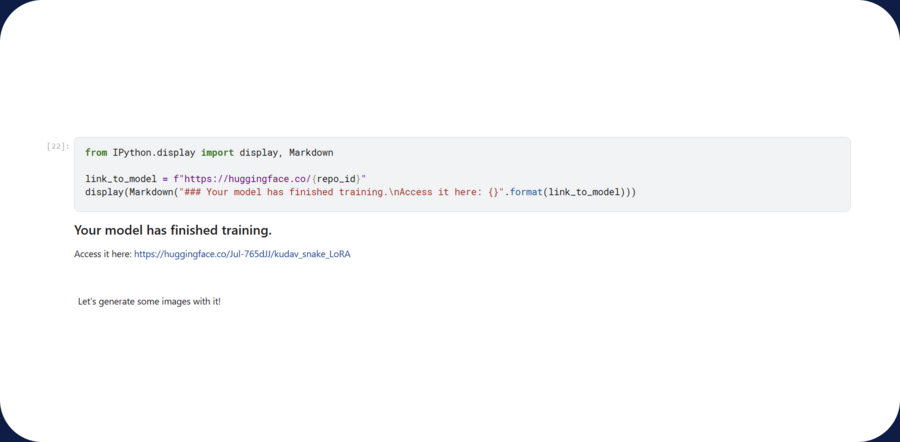

upload the model on Hugging Face
upload our model to generate images.
Result
The trained model captures Kudad’s features quite clearly. His face, color, tongue, and body can be clearly recognized on images. In the final generation, it’s evident that the model is short of 500 steps to capture the Kudad in an unmistakable way. However, the application of negative mist and a more detailed description do allow neuronets to understand the request. Couda’s heads disappear and leaves become more like leaves.
simple generation
More detailed generation using negative prom
I also want to add that I went to the image generation phase of a trained model with 1,000 steps, and unfortunately, in a series of endless Kaggle errors, I didn’t keep the output. But the model worked well, but Kudav was incredibly self-like, but neurosmelling really distorted his body, unnaturally bending out and adding his tongue to everything he could. Once I prescribed a negative prom, the images got much better and all the unnecessary artifacts went missing, showing the exact portrait of Kudava, so it’s worth concluding that the resulting model is worse than the intermediate failed option, and 1,000 steps should be taken to learn.
Description of the application of the generic model
Stable Diffusion XL, a model that is taught in the project, is used to generate final images of BLIP, and is used to write hits to photos from the Ghat GPT (https://openai.com/chatgpt/overview/) — helping to solve problems and correct incomprehensible errors
I also attach 2 laptops — the first with the name of the project — to this link is the final code. The second is my long- suffering first option, where there were 1,000 steps of learning, and for some reason, all the results of the launched cells were deleted.



