
Анализ данных о книгах бестселлерах
Вводная часть
Для финального проекта по курсу «Программирование для креативных индустрий» мной было выбрано проанализировать данные с сайта kaggle.com о книгах бестселлерах. В данных собрана информация о наиболее продаваемых книгах и сериях книг в различных жанрах и на разных языках. Оценки продаж основаны на количестве проданных экземпляров по всему миру. Для своего проекта я выбрала именно эти данные, поскольку я разрабатываю мобильное приложение для чтения книг, и мне захотелось подробнее изучить эту тему, чтобы применить в своем проекте.
Этапы работы
После того, как мной были выбраны данные, я приступила к их анализу, написанию кода, визуализации и стилизации графиков для придания им большей индивидуальности. Были использованы различные способы визуализации данных, такие как: линейные, столбчатые и круговые диаграммы. Эти графики наиболее подробно позволяют увидеть, например, временные тенденции или различия между категориями. По ходу работы я использовала сайты matplotlib.org, stackoverflow.com и нейросеть chatgpt, которые помогали мне найти ответы для написания качественного кода.
Для стилизации графиков мной была выбрана фирменная цветовая палитра моего приложения, которая использовалась для окраски как текста, так и графических элементов графиков. Также был использован шрифт PP Talisman Compact Regular, который придал графикам изящности, так подходящей для моей литературной темы.

шрифт и цветовая палитра
Для начала работы были загружены библиотеки для анализа данных и визуализации. Библиотека Pandas предоставляет инструменты для анализа и манипуляции данными, модуль Pyplot из библиотеки Matplotlib и библиотека Seaborn создают графики и диаграммы. С помощью Font Manager я смогла управлять шрифтами для стиллизации графиков. А при помощи функции read_csv из библиотеки Pandas я импортировала свой файл с данными.
Итоговые графики
Для начала я решила использовать линейный график, который помогает наглядно продемонстрировать, как общие продажи книг увеличивались от года к году.
Команда df.sort_values (’First published’, inplace=True) используется для сортировки данных по году первой публикации книги в порядке возрастания. Это необходимо, чтобы линейный график корректно отображал последовательность данных во времени, начиная с самого раннего года и заканчивая последним.
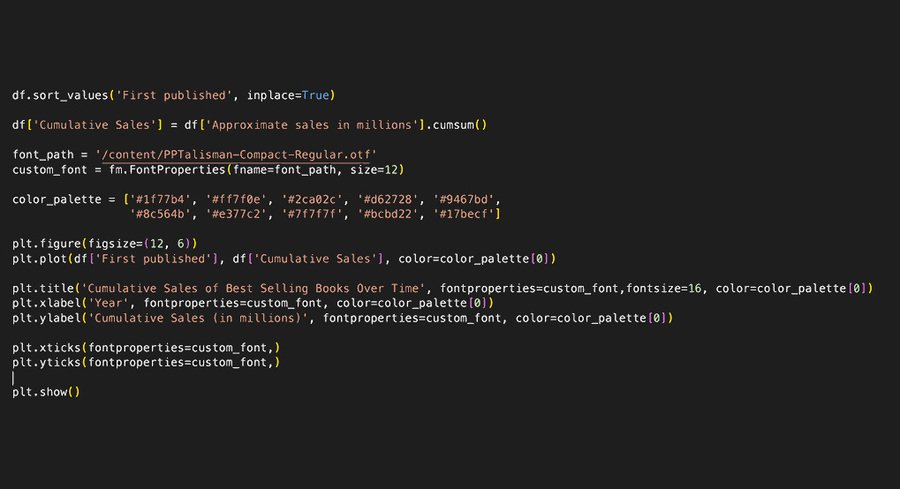
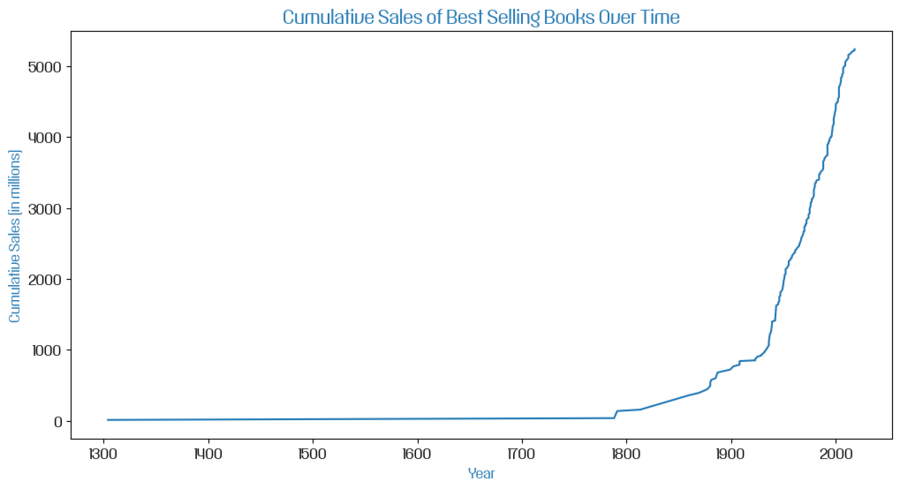
Линейный график увеличения продаж книг
Далее мне захотелось создать круговую диаграмму, которая показывает распределение десяти самых популярных жанров книг.
Сначала я подсчитала количество книг каждого жанра и вывела десять самых распространенных жанров. Затем использовала функцию custom_autopct, которая форматирует текст внутри секторов диаграммы. Если процентное значение сектора больше 2% от общего числа, то оно отображается; в противном случае текст не показывается. Это функция помогла мне вывести удобные для визуализации значения.
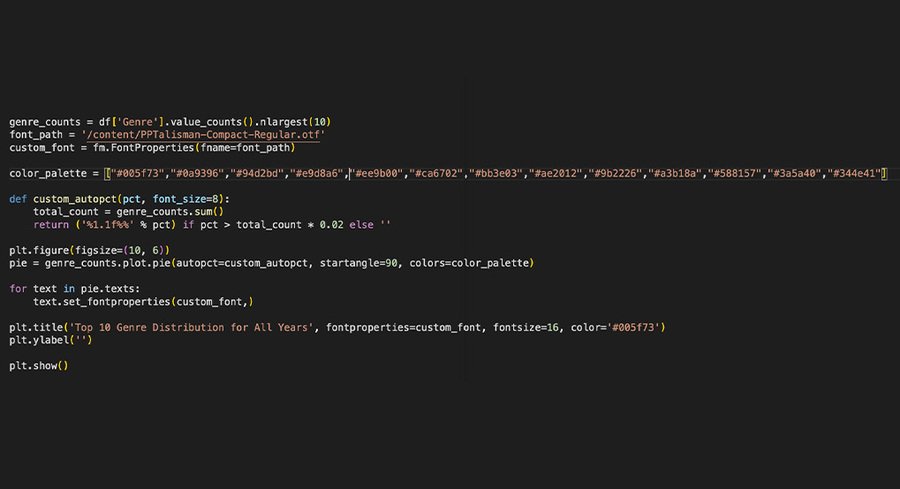
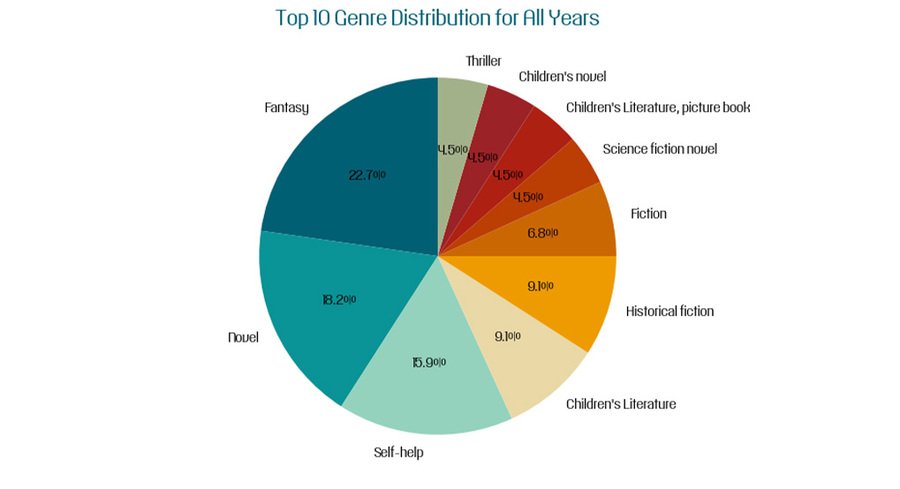
Круговая диаграмма распределения десяти самых популярных жанров книг
Я решила продолжить анализ по жанрам и создать столбчатую диаграмму для визуализации десяти жанров книг с самыми высокими продажами.
Я использовала библиотеки Matplotlib и Seaborn для создания визуализации, которая помогает легко сравнивать продажи. sns.barplot (…) — использует библиотеку Seaborn для создания столбчатой диаграммы с данными top_10_genres, осью X как ’Genre’, осью Y как ’Approximate sales in millions’ и кастомной палитрой random_colors.
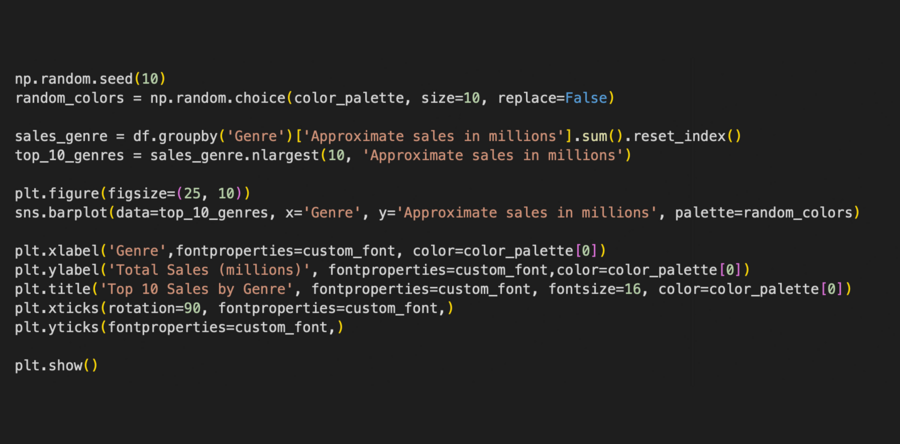
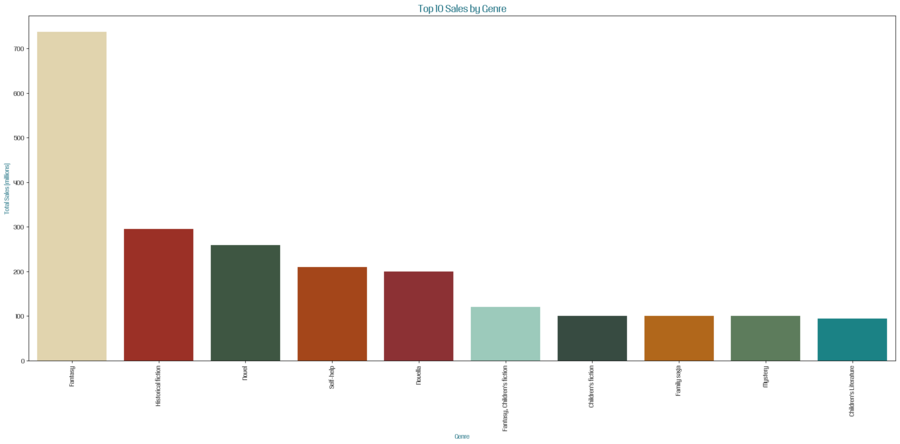
Столбчатая диаграмма десяти жанров книг с самыми высокими продажами
В поисках вдохновения я наткнулась на визуализацию данных с помощью библиотеки wordcloud. Я решила использовать этот прием для создания облака слов из названий самых продаваемых книг.
Для этого я импортировала класс WordCloud из библиотеки wordcloud, затем с помощью def custom_color_func (…) сделала выбор случайного цвета для каждого слова из своей палитры custom_color_palette.
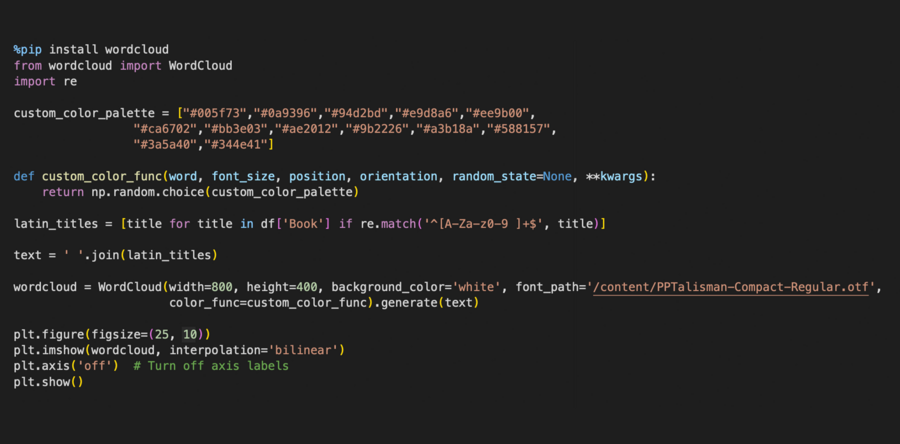

Облако слов из самых продаваемых названий книг
Также мне захотелось визуализировать с помощью столбчатой диаграммы общие продажи книг для двадцати авторов с наивысшими продажами.
Для этого я сгруппировала данные по авторам функцией groupby, суммировала (sum) приблизительные продажи в миллионах для каждого автора и выбрала двадцать авторов с самыми большими общими продажами (nlargest).
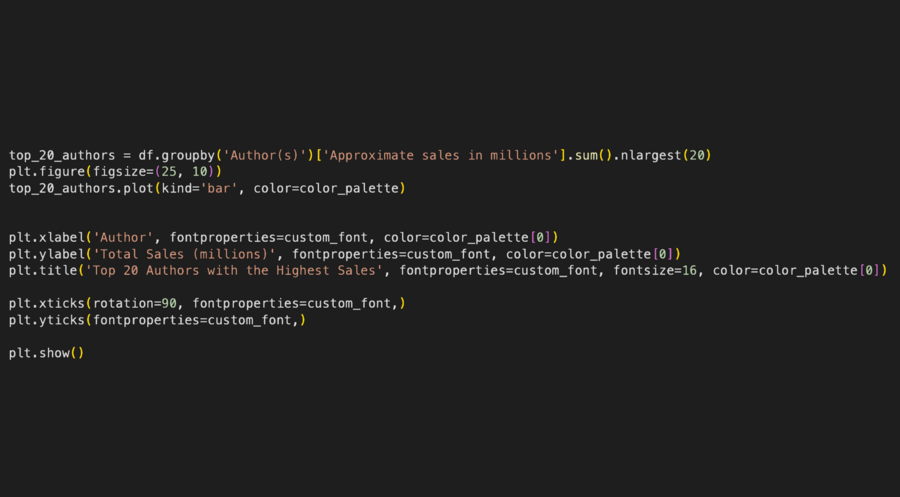
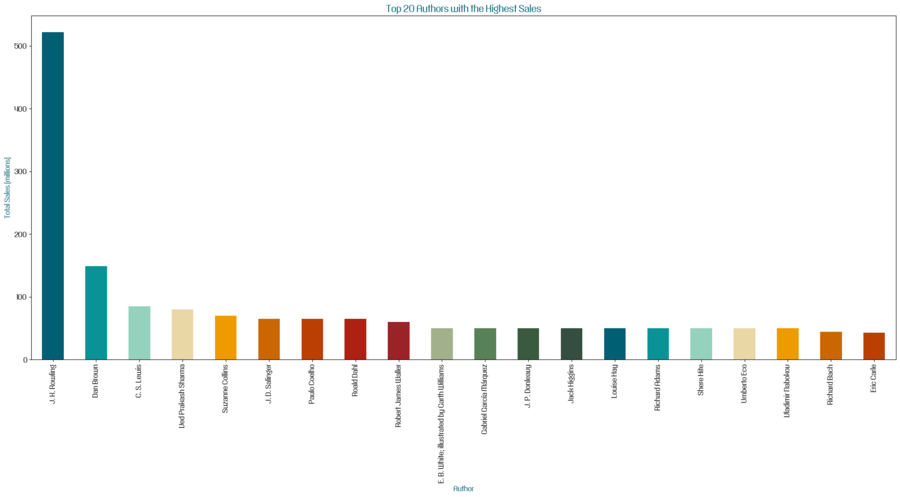
Столбчатая диаграмма общих продаж книг для двадцати авторов с наивысшими продажами
Кроме того, мне захотелось проанализировать данные о продажах книг, начиная с 1950-х годов, так как именно с этого времени замечен особый прирост. Для визуализации этой информации я выбрала линейный график, который лучше всего помогает визуализировать тренды с течением времени.
Для этого я преобразовала столбец ’First published’ в формат даты и времени, затем отфильтровала данные, оставляя только те записи, где год первой публикации начинается с 1950 года. Также сгруппировала данные по году первой публикации и суммировала продажи в миллионах для каждого года.
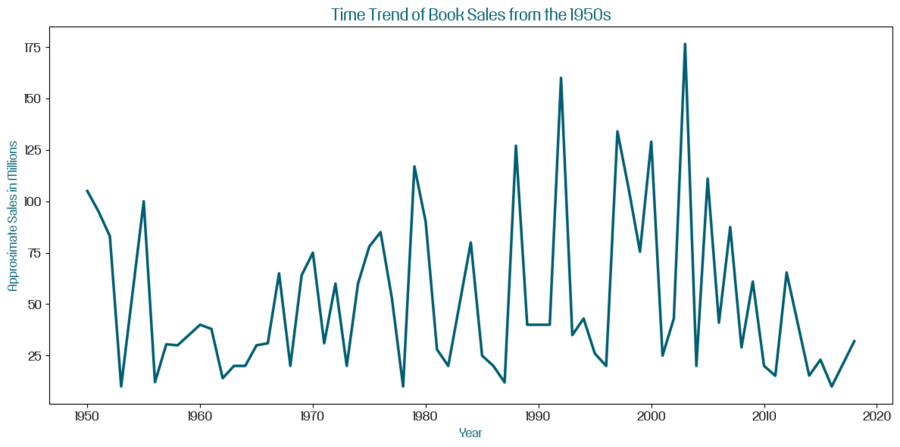
Линейный график данных о продажах книг от 1950-го года
В заключение я решила выяснить при помощи столбчатой диаграммы средние продажи и количество книг в каждом жанре.
Для этого я преобразовала столбец ’First published’ в формат даты и времени, отфильтровала публикации от 1950 года, сгруппировала данные по году первой публикации и вычислила сумму продажи в миллионах для каждого года, потом сгруппировала данные по жанру и вычислила средние продажи и количество книг в каждом жанре.
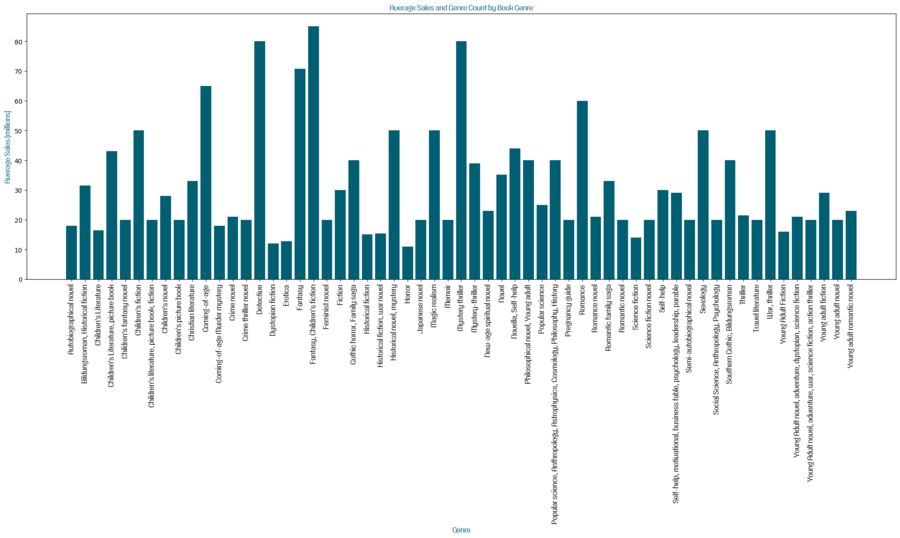
С помощью полученных данных я смогла узнать, какие жанры книг в среднем продаются лучше всего, выявить общую тенденцию продаж с течением времени, каковы текущие тренды в литературе и популярные темы. Изучение этих данных можно использовать для более глубокого понимания рынка, продаж, также можно дополнительно анализировать в контексте других факторов, таких как возрастная категория читателей, географическое распределение и изменения в популярности жанров в разные исторические периоды.
Описание применения генеративной модели
Для создании обложки проекта мной была использованная модель ideogram AI (https://ideogram.ai)
Промпт: A stunning 3D render illustration showcasing a vast library of colorfull books, with each volume appearing to float in mid-air. The books are surrounded by an array of data visualization symbols and graphics, including pie charts, bar graphs, and line graphs. The pure white background adds a sense of minimalism and elegance. The overall effect is a visually minimalistic representation of knowledge and information., 3d render — ar 4:3



