
this project does not exist
Год назад я парсил сайт portfolio.hse.ru чтобы сделать по этим данным проект по анализу данных.
В процессе я также скачал очень много обложек проектов — их я и решил использовать в качестве материала для обучения модели, чтобы нагенерить обложек для несуществующих проектов.
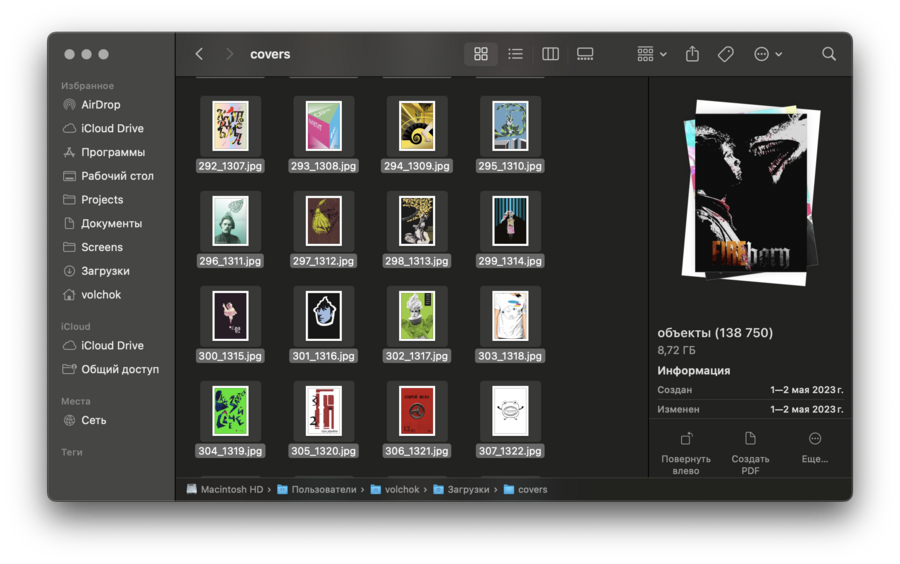
Процесс состоял из нескольких этапов: предобработки картинок, генерации промптов, создания выборки и обучения.
Обучение я провел двумя способами: первый — через генерацию промптов с BLIP, второй — с использованием в качестве промптов непрсредственно названий проектов.
Предобработка
Для первого метода поресайзил картинки и прогнал через BLIP.
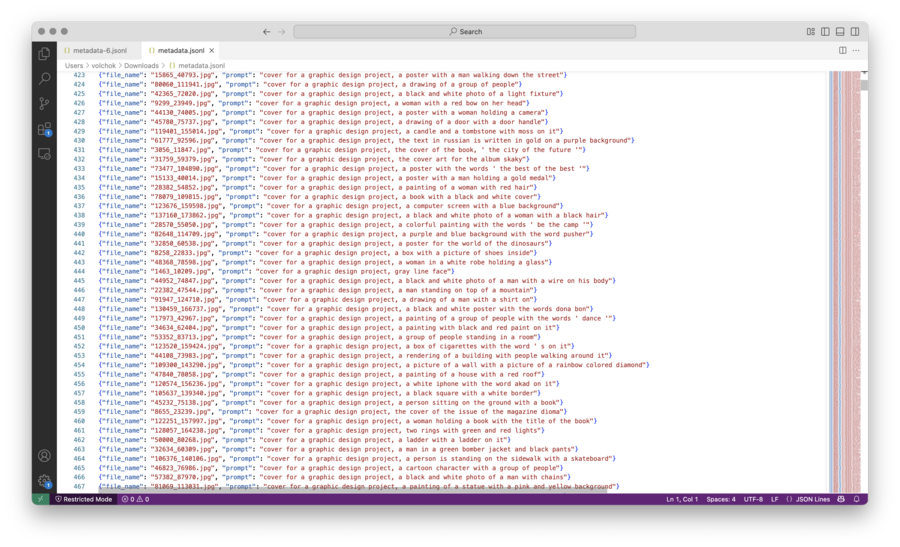
Потом собрал альтернативный датасет, где вместо BLIP использовал заранее скачанные названия проектов. Пришлось отобрать только проекты с английскими названиями, чтобы fine-tuning прошел лучше.
Обучение
По двум полученным датасетам дважды прогнал обучение, получив две вариации модели.
Генерация
Прежде чем генерить картинки, я решил нагенерить названия для проектов, чтобы потом использовать их в качестве промптов. Для этого собрал отдельную модельку на базе GPT-2, которую учил на датасете со всеми названиями проектов.
Далее в два захода (по двум датасетам) запустил генерацию
Результаты получились разные: чаще всего по запросам получаются абстрактные вещи, в основном из-за сложных промптов и очень разрозненных входных данных.


Но в целом, даже по искусственным запросам, часто получаются обложки, вполне похожие на что-то потенциально существующее в шд.




Модель любит в паттерны и типографику

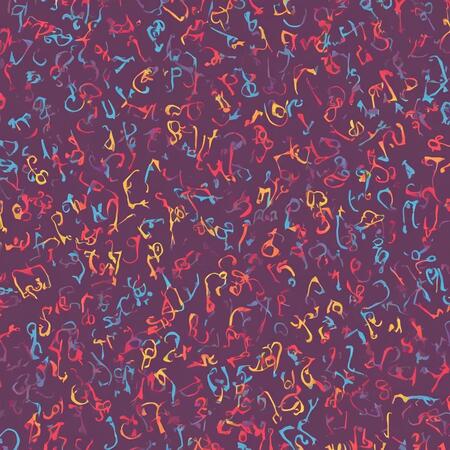
Где-то можно увидеть что-то от фешн-дизайна, где-то — от предметного


Есть и что-то похожее на проекты анимации и иллюстрации





