Статус иностранных компаний в России
Я выбрал датасет с сайта Kaggle. В датасете находятся данные по иностранным компаниям в России и их статусу, ушли ли они из России или остались.
Мне было интересно проанализировать состояние рынка сегодня и какой состав ушедших компаний на самом деле.
Для визуализации я выбрал гистограммы и стековые гистограммы.
Этапы работы
Сначала я изучил сам датасет. Там были следующие виды данных: - название компании - деятельность компании (свернули бизнес, остались, продали и т. д.) - категория по шкале университета Йеля - код страны - название страны - индустрия, в которой работает компания
Затем я писал промпты в нейросеть ChatGPT для обработки данных: - распределение компаний по категориям YaleGrade - топ-10 стран с наибольшим количеством компаний - распределение компаний по индустриям - сравнение количества компаний, ушедших из РФ и оставшихся
Пример визуализации:
plt.figure (figsize=(12, 8)) data['country'].value_counts ().plot (kind='bar', color='teal', edgecolor='black') plt.title ('Распределение компаний по странам', fontsize=14) plt.xlabel ('Страна', fontsize=12) plt.ylabel ('Количество компаний', fontsize=12) plt.xticks (rotation=90) plt.tight_layout () plt.show ()
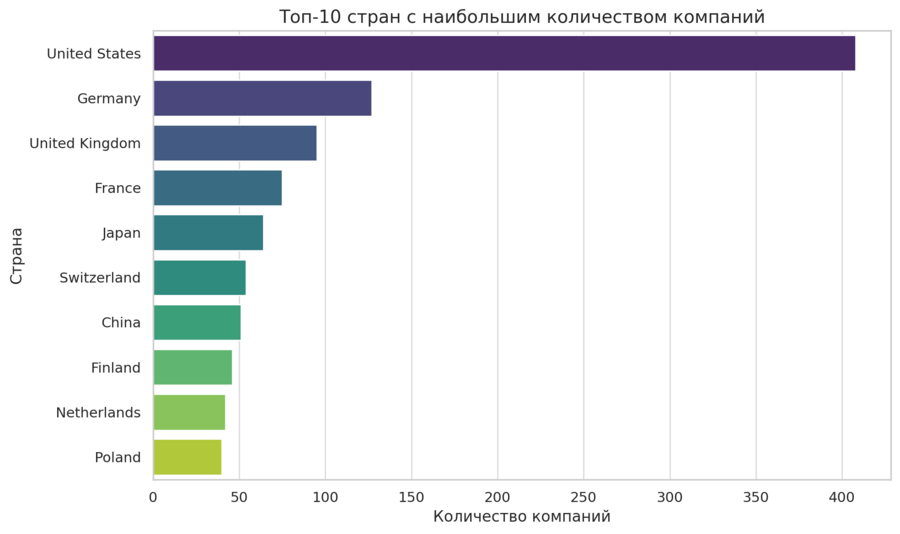
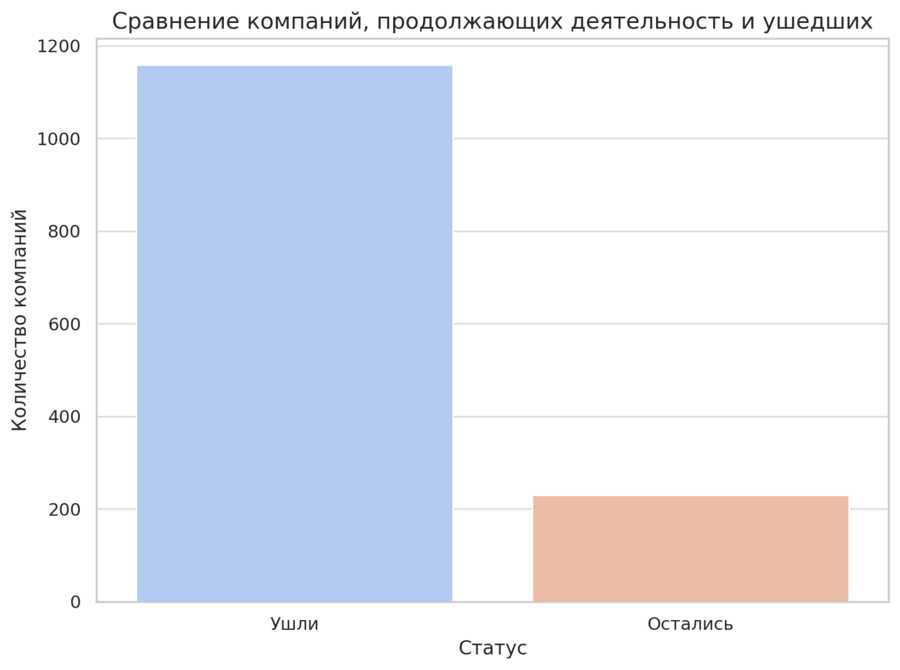
Описание применения генеративной модели
Использовалась модель ChatGPT для генерирования Python кода обработки и визуализации данных.
Использовалась модель Kandinsky для генерирования обложки



")